
The World’s Fastest Database Just Got Faster
At SingleStore, we’re on a mission to create the world’s best database. On our path to achieve that goal, today we announced our latest product, SingleStoreDB Self-Managed 6.5, is generally available.
As the no-limits database™, SingleStore provides maximum performance, scalability, and concurrency for your most important applications and analytical systems. This latest release further improves on what customers love about SingleStore, advancing performance and adding capabilities to accelerate time to insight and simplify operations.
Today, the pace of innovation and competition means that businesses are asking more and more of their technology teams. You must provide flawless customer experiences. The business relies on you for consistently fast insights. And you must create and scale these systems as quickly as possible. To meet these demands, SingleStore allows customers to run both transactional and analytical workloads at web scale with a single database — all without having to abandon familiar, standard SQL.
This means that whether you are building a new application, modernizing existing applications or infrastructure, or trying to improve database performance, SingleStore can help everyone quickly achieve the results business demands without having to learn a host of new tools or abandon existing application logic.
New advancements in SingleStoreDB Self-Managed 6.5 take these abilities even further.
Experience Latency-Free Queries
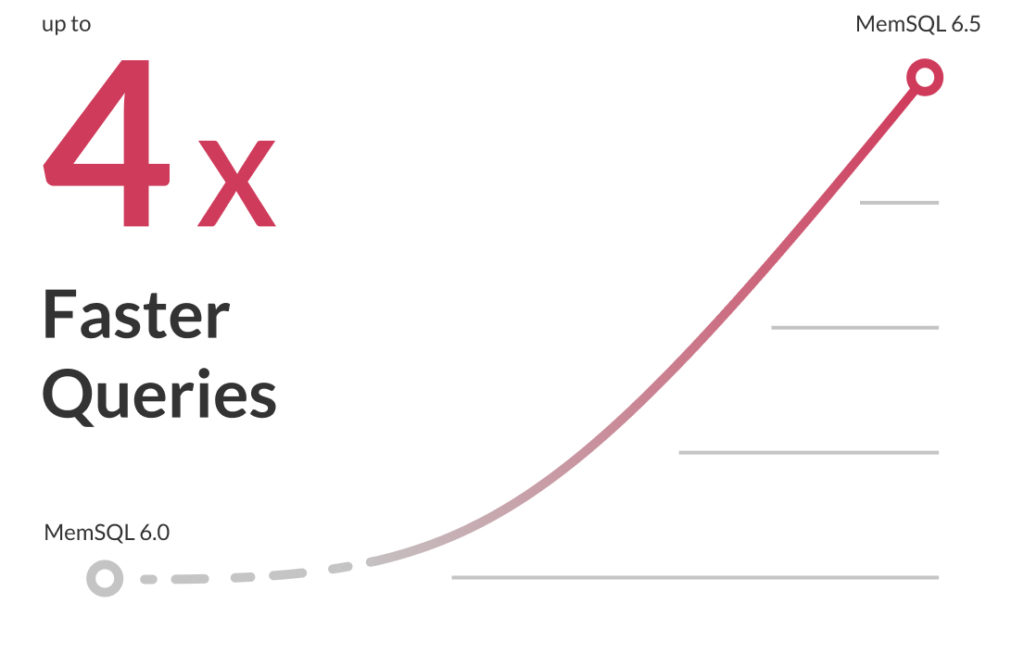
The world’s fastest SQL database just got faster. Customers – whether end or internal users – have no tolerance for latency. Faster database response times means more data can be analyzed more frequently while improving the accuracy of insights.
SingleStoreDB Self-Managed 6.5 has made queries 2-4x faster than the previous version (which was already 10x faster than legacy database providers) and improves data ingestion speeds for high data volume applications. A series of query improvements extends breakthrough performance of group-by, joins, and filter queries to deliver insights in milliseconds across billions of rows.
Deliver Performance at High Concurrency with Enhanced Workload Optimization
Data professionals spend hours trying to manage database performance for fast growing data and user access. In the face of extreme workloads, automated workload management provides consistent database response without the help of experts.
While under high concurrency, SingleStore automatically delivers reliable database performance to easily support growth in application users and queries.Our autonomous workload manager inspects and queues high volume queries to deliver the best possible response for all types of queries.
Build Real-time Data Pipelines with Stored Procedures
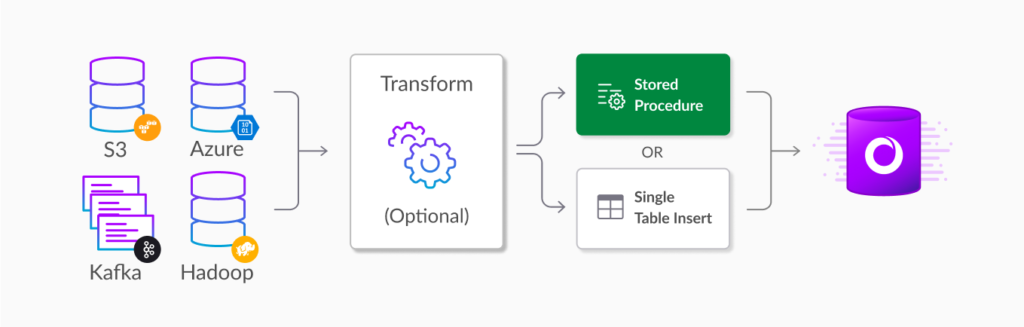
Building scalable data pipelines to handle data ingestion often requires additional tooling that is costly, complex to use, and difficult to deliver reliable performance. SingleStore provides built-in pipelines for technologies such as Kafka, Amazon S3, and others to provide a more efficient architecture that delivers record breaking ingestion performance without the complexity of third-party tools.
With 6.5, SingleStore Pipelines extends its industry leading “transform-as-you-ingest” capabilities with new in-database transformations using stored procedures. The result is more powerful programmatic pipelines that give developers more control for machine learning and data enrichment operations on streams of data, eliminating the cost and complexity of separate ETL tooling.
Easily Scale Your Multi-tenant Cloud Application
Managing a multi-tenant service can prove challenging due to unpredictable data and user growth along with limitations on where the service can run. The result is over or under provisioning resources along with getting locked into a cloud provider impacting service performance and costs.
With SingleStoreDB Self-Managed 6.5, new resource optimizations help deliver a more tailored, scalable multi-tenant database environment you can deploy anywhere, including on-premises or public cloud with the ease of scale to meet the changing demands of your application. The result is a no-limits database that performs in the most optimized and efficient way, regardless of the size or scale of your application.
Extend Insights to More Data with Full-Text Search
Roughly 80 percent of all data is unstructured, including text data, so there is a need to provide a solution that organizes and analyzes that data for modern applications. Building text-search into modern applications often means specialized tooling that requires additional expertise and management overhead.
SingleStore has full-text search built in, so developers can more easily deliver fast, scalable full text capabilities with keyword-based and regular query conditions in a single SQL statement. The addition of text search to SingleStoreDB Self-Managed 6.5 eliminates the need for a separate specialized data store, allowing you to simplify architecture and improve overall performance.
Get Improved Data Pipeline Support for Hadoop
While Hadoop provides a cost-effective environment to store data, it has become insufficient for high performance analytics at-scale. With a fast relational database, data architects and scientists can combine HDFS with scalable SQL to deliver faster insights with the familiar language everyone understands.
The new SingleStore HDFS data pipeline delivers continuous ingestion from data lakes into a structured relational format to deliver faster analytics using the familiarity of ANSI SQL.
Want to Learn More?
Attend our webinar: Learn more details and see a demo of the new capabilities in SingleStoreDB Self-Managed 7.3
Try Now: Get a free evaluation of SingleStoreDB Self-Managed 7.3





