November is nearly upon us, with the spotlight on Election 2016. This election has been amplified by millions of digital touchpoints. In particular, Twitter has risen in popularity as a forum for voicing individual opinions as well as tracking statements directly from the candidates. Pew Research Center states that “In January 2016, 44% of U.S. adults reported having learned about the 2016 presidential election in the past week from social media, outpacing both local and national print newspapers.” The first 2016 Presidential debate “between Donald Trump and Hillary Clinton was the most-tweeted debate ever. All told, there were 17.1 million interactions on Twitter about the event.”
By now, most people have probably seen both encouraging and deprecating tweets about two candidates: Hillary Clinton and Donald Trump. Twitter has become a real-time voice for the public watching along with debates and campaign announcements. We wanted to hone in on the sentiments expressed in real time. Using Apache Kafka, SingleStore, Machine Learning and our Pipelines Twitter Demo as a base, we are bringing real-time analytics to Election 2016.

Click here to access the live demo
Post-Election, we have shut down the demo. View a screencap of it running at the bottom of this post.
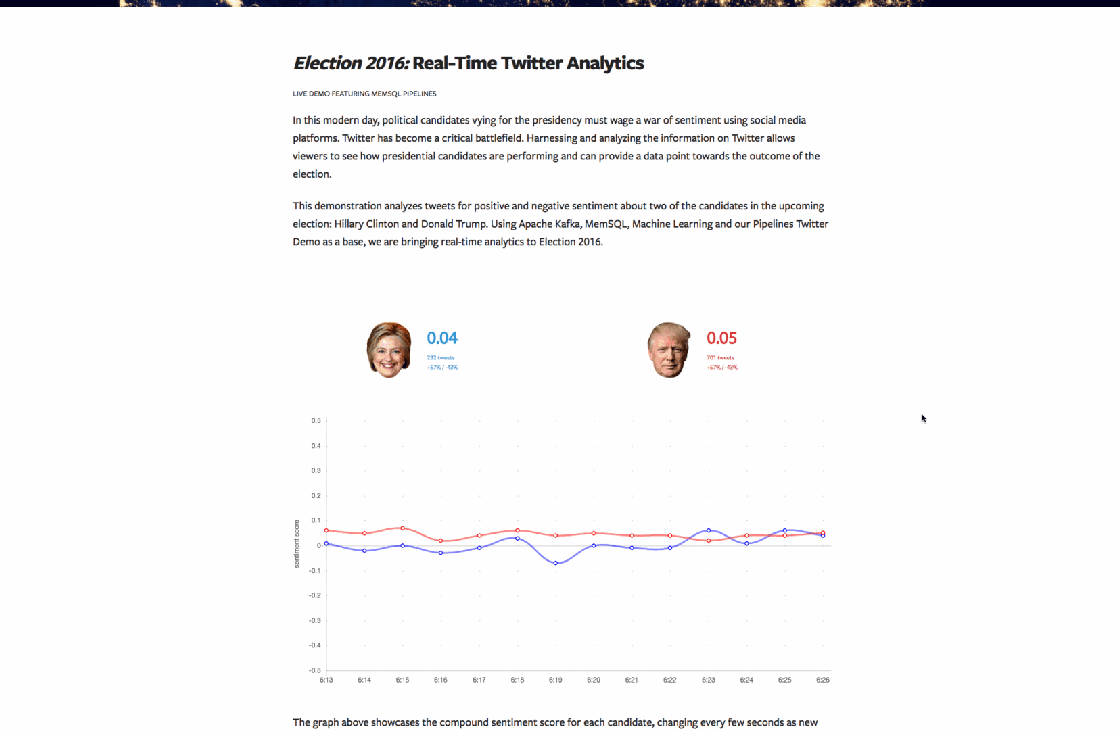
Introducing our latest live demonstration, Election 2016: Real-Time Twitter Analytics. We analyze the sentiment –attitude, emotion, or feeling– of every tweet about Clinton and Trump as it is tweeted. Now, anyone can see how high or low in the negative or positive tweets are trending at any given point. We’re giving everyone access to the broader scope of how each candidate is doing according to the Twittersphere.
How it Works
First, we wrote a python script to collect tweets and retweets that contain the words Hillary, hillary, Trump, or trump directly from Twitter.com. We picked the words “Hillary” and “Trump” as descriptors since they are the most used for the candidates. The script pushes this content to an Apache Kafka queue in real time. Messages in this Kafka queue are then streamed using SingleStore Pipelines. Released in September 2016 at Strata+Hadoop World, Pipelines features a brand new SQL command CREATE PIPELINE, enabling native ingest from Apache Kafka and creation of real-time streaming pipelines.
The CREATE PIPELINE statement looks like this:
CREATE PIPELINE `twitter_pipeline`
AS LOAD DATA KAFKA ‘your-kafka-host-ip:9092/your-kafka-topic’
INTO TABLE `tweets`
The CREATE TABLE statement for the tweets table in SingleStore is shown below:
CREATE TABLE `tweets` (
`id` bigint(20) DEFAULT NULL,
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`tweet` JSON COLLATE utf8_bin,
`text` as tweet::$text PERSISTED text CHARACTER SET utf8 COLLATE utf8_general_ci,
`retweet_count` as tweet::%retweet_count PERSISTED int(11),
`candidate` as CASE
WHEN (text LIKE '%illary%') THEN 'Clinton'
WHEN (text LIKE '%rump%') THEN 'Trump'
ELSE 'Unknown' END PERSISTED text CHARACTER SET utf8 COLLATE utf8_general_ci,
`created` as FROM_UNIXTIME(`tweet`::$created_at) PERSISTED datetime,
KEY `id` (`id`) /*!90619 USING CLUSTERED COLUMNSTORE */,
/*!90618 SHARD */ KEY `id_2` (`id`)
)
Note: we create tweets as a columnstore table so it can handle large amounts of data for analytics. We also utilize persisted computed columns in SingleStore to parse JSON data for categorizing each tweet by candidate. SingleStore natively supports the JSON data format.
When the twitter_pipeline is run, data in the tweets table looks like this:
memsql> SELECT * from tweets LIMIT 1\G
*************************** 1. row ***************************
id: 786409507039485952
ts: 2016-10-13 03:33:53
tweet:{"created_at":1476329611,"favorite_count":0,"id":786409507039485952,"retweet_count":0,"text":"RT @BlackWomen4Bern: This will be an interesting Halloween this year...expect me to tweet some epic Hillary costumes...I expect there will…","username":"hankandmya12"} text: RT @BlackWomen4Bern: This will be an interesting Halloween this year...expect me to tweet some epic Hillary costumes...I expect there will…
retweet_count: 0
candidate: Clinton
created: 2016-10-13 03:33:31
1 row in set (0.03 sec)
Next, we created a second pipeline that pulled from the same Kafka topic, but instead of storing directly into a table, we perform real-time sentiment analysis with a SingleStore Pipelines transform that leverages the Python Natural Language Toolkit (nltk) Vader module. The CREATE PIPELINE statement for the second pipeline looks like this:
CREATE PIPELINE `twitter_sentiment_pipeline`
AS LOAD DATA KAFKA 'your-kafka-host-ip:9092/your-kafka-topic'
WITH TRANSFORM ('http://download.singlestore.com/pipelines-twitter-demo/transform.tar.gz' , 'transform.py' , '')
INTO TABLE `tweet_sentiment`
Combining data from these two SingleStore pipelines, we can perform analytics using SQL. For example, we can create a histogram of tweet sentiment through the following query:
SELECT
sentiment_bucket,
SUM(IF(candidate = "Clinton", tweet_volume, 0)) as clinton_tweets,
SUM(IF(candidate = "Trump", tweet_volume, 0)) as trump_tweets
FROM tweets_per_sentiment_per_candidate_timeseries t
GROUP BY sentiment_bucket
ORDER BY sentiment_bucket;
Lastly we constructed a User Interface (UI). We built the graph using WebSockets and React to visualize the rolling average tweet sentiment for both candidates, drawn in real time.
Click here to access the live demo
Post-Election, we have shut down the demo. View a screencap of it at the bottom of this post.
Stream Twitter data into SingleStore as shown here by following these instructions: https://github.com/memsql/pipelines-twitter-demo
Try SingleStore Pipelines today! Download the latest version of SingleStore at singlestore.com/cloud-trial/