The urgency for IT leaders to bring real-time analytics to their organizations is stronger than ever. For these organizations, the ability to start with fresh data and combine streaming, transactional, and analytical workloads in a single system can revolutionize their operations.
When moving from batch to real time, data architects should carefully consider what type of streaming semantics will optimize their workload. The table below highlights the nuances among different types of streaming semantics.
Understanding Streaming Semantics
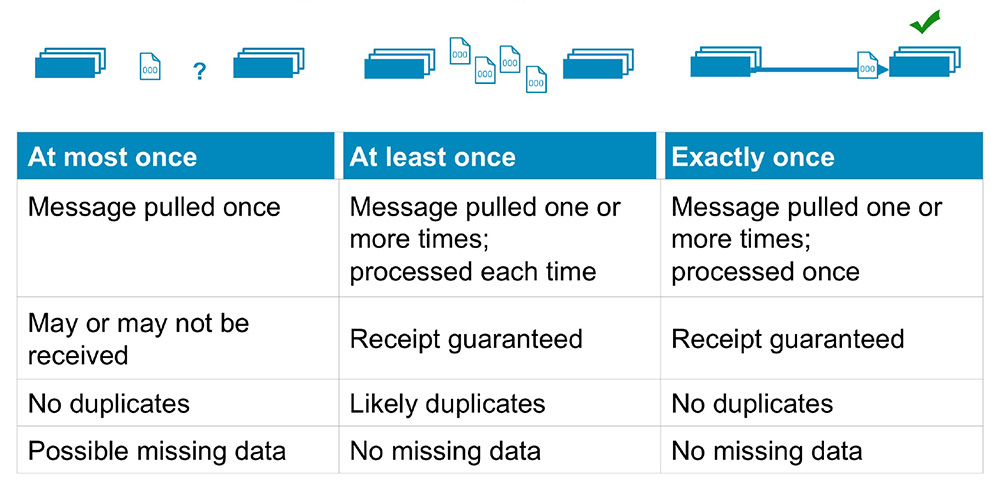
At Most Once\With at most once semantics, a message is pulled once, but is not guaranteed to be received. At most once semantics conserves bandwidth and does not produce duplicates, but leaves us with a possibility of missing data.
At Least Once\At least once semantics pulls messages one or multiple times to guarantee every message is received. However, doing so consumes an unnecessary amount of network bandwidth and increases the likelihood of duplicate records being entered into the system, that ultimately need to be consolidated.
Exactly-Once\With exactly-once semantics, messages are pulled one or more times, processed only once, and delivery is guaranteed. Exactly-once semantics is ideal for operational applications, as it guarantees no duplicates or missing data. Many enterprise applications, like those used for credit card processing, require exactly-once semantics.
Exactly-Once Semantics for Apache Kafka
We recently launched SingleStore Pipelines, making it easier than ever to achieve real-time data ingestion at scale. SingleStore Pipelines ensures exactly-once semantics when streaming from message brokers like Apache Kafka.