
Data is driving innovative customer experiences, operation optimization, and new revenue streams. Data infrastructure teams are being asked to update their legacy infrastructure to respond to changing business conditions without disrupting existing operations. The future of data management is modernizing legacy systems using real-time data synchronization with modern databases that can accelerate innovation without impacting existing applications.
The Challenge of Legacy Systems
A constant challenge of legacy systems is the need to create new growth opportunities with a lower total cost of ownership while keeping current production systems running. In other words, without impacting production systems used by both enterprise users and application services, there needs to be a way to transform batch-based applications to real-time applications.
In this blog post, we examine how easy it is to “have our cake and eat it, too”. SingleStore helps enterprises implement modern data applications without disrupting existing enterprise application architectures.
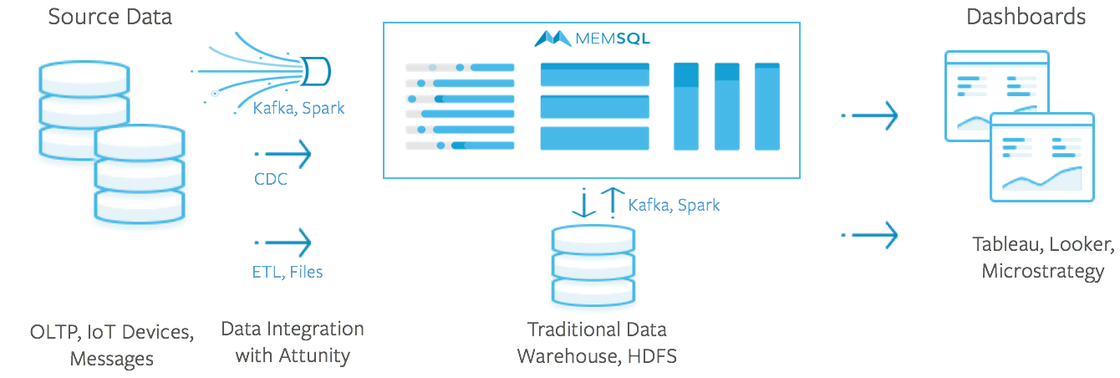
For example, take the fairly typical and traditional approach below for deriving value from business data.
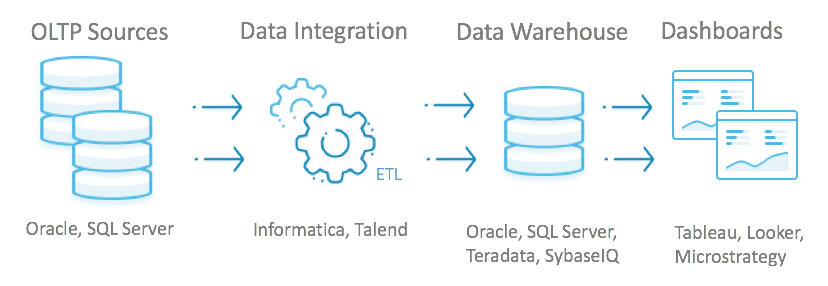
Built over 20 years ago, this approach requires batch processing of data, which is time consuming and subject to costly failures. Data is batch loaded from the transactional database into the analytics data warehouse. A tremendous amount of time and processing power is required to extract, transform, and load the batched data. Once loaded into the data warehouse, business intelligence tools generate reports and ad-hoc analyses.
A Failed Batch is like a Clogged Pipe
However, if one batch contains errors and needs to be reloaded, the time it takes to reload the repaired data immediately starts to impact the queue of current batches. Very quickly, a backlog of batches grows. This creates a clogged pipe of enterprise data. And for this reason, legacy architectures that rely on batch processing fails to meet the real-time requirements that modern applications demand.
CDC and SingleStore to the Rescue
Using a Change Data Capture (CDC) solution and SingleStore, it is easy to augment the traditional enterprise data architecture, and transform it into a modern powerhouse. SingleStore quickly and easily plugs into the legacy ecosystem without disrupting it, as do many CDC solutions. This allows companies to leverage legacy investments while enabling real-time applications, machine learning, and artificial intelligence.
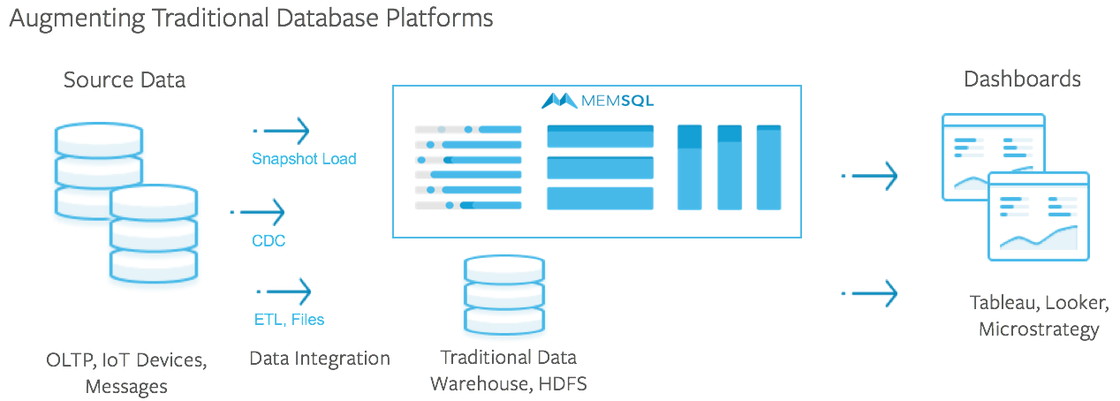
Implement CDC and SingleStore
In today’s market, there are various CDC vendors including Attunity, DBVisit, GoldenGate, HVR Replicate, and others. For all CDC solutions, the steps to implement them are relatively similar. You can start migrating data to SingleStore with any of these CDC solutions without impacting the source database application.
Step 1: Create the source database objects in SingleStore
With SingleStore as part of your ecosystem, it’s easy to create the existing database objects. Some of the CDC solutions will generate the required Data Definition Language (DDL) and automatically create them in SingleStore as part of the initial-load process. We also have a small Java utility ‘GenMemDDL’ to generate the DDL if needed.
Step 2: Load a snapshot of the source data into SingleStore
First, start the process to create a snapshot of the source database. The data will get batched and written to SingleStore. During the snapshot load, a change-synchronization process captures the incremental data changes made on the source system. Those changes are applied to SingleStore after the snapshot load is complete.
Depending on the network speed and the data size, the copying of historical data can take hours or days. But since this is a background process managed by the CDC tool, there is no downtime to active users in the production environment.
Using Attunity Replicate for Building CDC Applications
Attunity Replicate is an industry-standard CDC solution. Attunity enables transactional change data capture between operational and analytical enterprise systems. Attunity also supports generating DDL from the source database directly into SingleStore, eliminating the need to do the conversion manually.
The initial data load method extracts data from an Oracle source table to a CSV file format. Next, using a LOAD DATA command, Attunity loads data file into SingleStore. Depending on your dataset, you can specify the file size.
For a sanity check, we’ll do a count of the tables in the Oracle database source:
SOE> @counts
LOGON WAREHOUSES ORDER_ITEMS CUSTOMERS ADDRESSES INVENTORIES ORDERS CARD_DETAILS PRODUCT_DESCRIPTIONS
———- ———- ———– ———- ———- ———– ———- ———— ——————–
PRODUCT_INFORMATION ORDERENTRY_METADATA
——————- ——————-
714895 1000 1286818 300000 450000 899903 428937 450000 1000
1000 0
First, create the Oracle source and SingleStore target connection definition in Attunity. The connection information is in the odbc.ini file in /etc on your Linux midtier server.
Next, create an Attunity Task to define the source and target:
As part of the Task setup, select the source tables to replicate:

Start the task, and Attunity will replicate the data for the selected table from Oracle to SingleStore. Once the task is complete, you can do a count on SingleStore to confirm the data matches.
memsql> source counts.sql+——–+————+————-+———–+———–+————-+——–+————–+———————-+———————+———————+
| LOGON | WAREHOUSES | ORDER_ITEMS | CUSTOMERS | ADDRESSES | INVENTORIES | ORDERS | CARD_DETAILS | PRODUCT_DESCRIPTIONS | PRODUCT_INFORMATION | ORDERENTRY_METADATA |
+——–+————+————-+———–+———–+————-+——–+————–+———————-+———————+———————+
| 714895 | 1000 | 1286265 | 300000 | 450000 | 899903 | 428937 | 450000 | 1000 | 1000 | 0 |
+——–+————+————-+———–+———–+————-+——–+————–+———————-+———————+———————+
1 row in set (0.05 sec)
Step 3: Apply the CDC data into SingleStore
While the initial load task runs, Attunity also captures all the changes made by the application users and services on the source system. The CDC solution serializes a queue of the data changes. Once the initial load completes, Attunity applies the queue of changes to SingleStore.
The active queue of changes serves as the synchronization mechanism between the source database and SingleStore. The CDC solution captures all newly committed transactions and replicates the new transactions to SingleStore.
Depending on how much data has been queued, it will take some time to apply those changes. Once all the changes have been applied, SingleStore is now completely synchronized with the source.
With CDC and SingleStore, Data is Ready for Real Time
With CDC solutions such as Attunity Replicate, it is easy to migrate and synchronize production databases and data warehouses with SingleStore. Most importantly, the production systems are not affected. System users and application services continue to run without downtime. And you don’t have to worry about batch processing causing clogs in your data pipes.
With SingleStore as a vital technology in your enterprise ecosystem, you can leverage your legacy investment and start building real-time applications.
For SingleStore to work with Attunity Replicate, you will need a patch for your Attunity environment. Contact us to get the patch, and we’ll help you get started.





