
Disclaimer. This will not be an apples to apples comparison with derwik, since we obviously don’t have the same dataset, and we need a much bigger machine to load everything into memory. But I believe this experiment will get the point across. So without further ado, let’s go through the steps.
Adam Derewecki wrote a cool post about his experience loading half a billion records into MySQL. SingleStore is a MySQL-compatible drop-in replacement that is built from the ground up to run really fast in memory.
Disclamer: this isn’t an apples-to-apples comparison with derwik since we don’t have his dataset and need a much beefier machine to load everything into memory.
Schema
Here is the schema for the table. Note that the table has three indexes. On top of it memsql will automatically generate a primary index under the covers. We won’t be disabling keys.
drop table if exists store_sales_fact;
create table store_sales_fact(
date_key smallint not null,
pos_transaction_number integer not null,
sales_quantity smallint not null,
sales_dollar_amount smallint not null,
cost_dollar_amount smallint not null,
gross_profit_dollar_amount smallint not null,
transaction_type varchar(16) not null,
transaction_time time not null,
tender_type char(6) not null,
product_description varchar(128) not null,
sku_number char(12) not null,
store_name char(10) not null,
store_number smallint not null,
store_city varchar(64) not null,
store_state char(2) not null,
store_region varchar(64) not null,
key date_key(date_key),
key store_region(store_region),
key store_state(store_state)
);
Hardware
We have a very cool machine, with 64 cores and 512 GB of RAM, from Peak Hosting . You can rent one for yourself for a little under two grand a month. They were kind enough to give it to us to use for free. Here is a spec of one core.
vendor_id : AuthenticAMD
cpu family : 21
model : 1
model name : AMD Opteron(TM) Processor 6276
stepping : 2
cpu MHz : 2300.254
cache size : 2048 KB
You read that correctly, this machine has sixty-four 2.3 GHz cores and 512 GB of RAM or almost 8 times the largest memory footprint available in the cloud today, all on dedicated hardware with no virtualization overhead or resource contention with other unknown third parties.
Loading efficiently
Loading data efficiently is actually not that trivial. The best way of doing it with SingleStore is to use as much CPU as you can get. Here are a few tricks that can be applied.
1. Multi-inserts
We can batch inserts into 100 row multi-inserts. This will reduce the number of network roundtrips. Each roundtrip now accounts for 100 rows instead of one. Here is what multi-inserts look like.
insert into store_sales_fact values('1','1719','4','280','97','183','purchase','14:09:10','Cash','Brand #6 chicken noodle soup','SKU-#6','Store71','71','Lancaster','CA','West'),
('1','1719','4','280','97','183','purchase','14:09:10','Cash','Brand #5 golf clubs','SKU-#5','Store71','71','Lancaster','CA','West'),
('1','1719','4','280','97','183','purchase','14:09:10','Cash','Brand #4 brandy','SKU-#4','Store71','71','Lancaster','CA','West'),
2. Load in parallel.
Our customer has a sample file of 510,593,334 records. We can use the command line mysql client to pipe this file into SingleStore, but this would not leverage all the cores available in the system. So ideally we should spit the file to at least as many chunks as there are CPUs in the system.
3. Increase granularity
Splitting the file into 64 big chunks will introduce a data skew. The total data load time will be the time the slowest thread loads the data. To address this problem we will split the file into thousands of chunks. And every time a thread frees up we will start loading another chunk. So we split the file into 2000 chunks.
1 -rw-r--r-- 1 35662844 2012-06-06 11:42 data10.sql
2 -rw-r--r-- 1 35651723 2012-06-06 11:42 data11.sql
3 -rw-r--r-- 1 35658433 2012-06-06 11:42 data12.sql
4 -rw-r--r-- 1 35663665 2012-06-06 11:42 data13.sql
5 -rw-r--r-- 1 35667480 2012-06-06 11:42 data14.sql
6 -rw-r--r-- 1 35659549 2012-06-06 11:42 data15.sql
7 -rw-r--r-- 1 35661617 2012-06-06 11:42 data16.sql
8 -rw-r--r-- 1 35650414 2012-06-06 11:42 data17.sql
9 -rw-r--r-- 1 35661625 2012-06-06 11:42 data18.sql
10 -rw-r--r-- 1 35667634 2012-06-06 11:42 data19.sql
11 -rw-r--r-- 1 35662989 2012-06-06 11:42 data1.sql
4. Load script. The load script uses python multiprocessing library to load data efficiently.
1 import re
2 import sys
3 import os
4 import multiprocessing
5 import optparse
6
7 parser = optparse.OptionParser()
8 parser.add_option("-D", "--database", help="database name")
9 parser.add_option("-P", "--port", help="port to connect. use 3306 to connect to memsql and 3307 to connect to mysql", type="int")
10 (options, args) = parser.parse_args()
11
12 if not options.database or not options.port:
13 parser.print_help()
14 exit(1)
15
16 total_files = 2000
17
18 def load_file(filename):
19 try:
20 print "loading from cpu: %d" % os.getpid()
21 query = 'mysql -h 127.0.0.1 -D %s -u root -P %d < %s' % (options.database, options.port, filename)
22 print query
23 os.system(query)
24 print "done loading from cpu: %d" % os.getpid()
25 except e as Exception:
26 print e
27 pass
28
29 os.system('echo "delete from store_sales_fact" | mysql -h 127.0.0.1 -u root -P %d' % options.port)
30 p = multiprocessing.Pool(processes = 2*multiprocessing.cpu_count())
31 for j in range(0, total_files):
32 p.apply_async(load_file, ['data/data%d.sql' % j])
33
34 p.close()
35 p.join()
5. Running it
I started loading by issuing the following command.
time python load.py -D test -P 3306After we do this let’s start htop to check the processor saturation. It looks pretty busy.
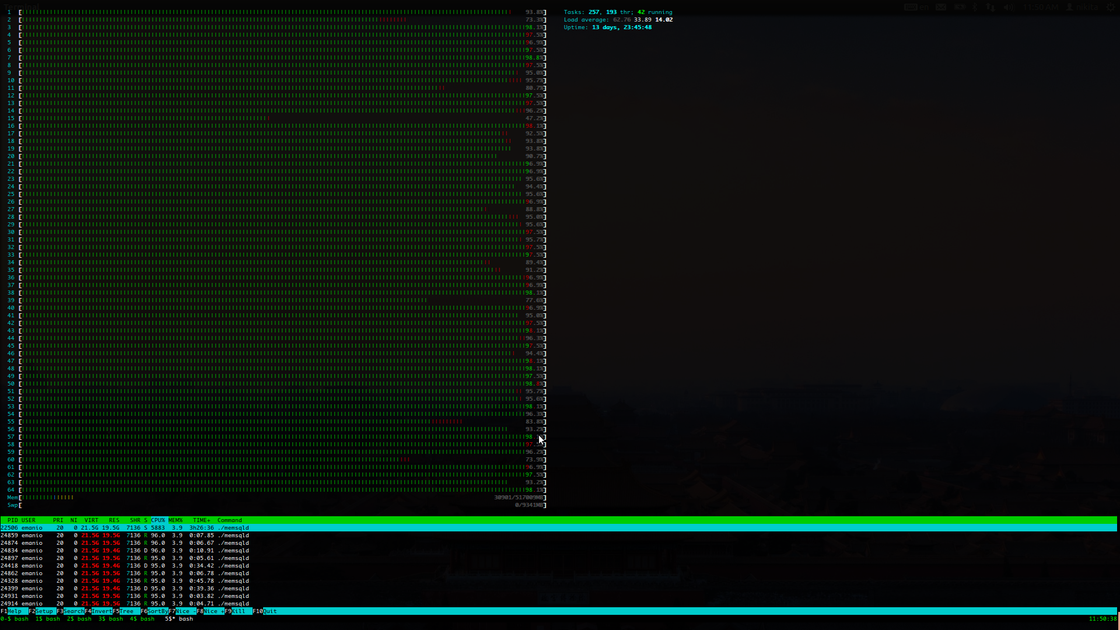
Processor saturation
SingleStore uses lockfree data structures that eliminate a lot of contention.
It took a bit of time, but the data has been loaded.
real 39m21.465s
user 33m53.210s
sys 5m24.470s
The result is almost 200K inserts a second for a table with 4 indexes. The memory footprint of the memsql process is 267 Gb.
Running the same test against mysql
I would not be fair to skip comparison with mysql, particularly that it’s so easy to do since memsql uses mysql wire protocol and support mysql syntax. I used the my.cnf settings from http://derwiki.tumblr.com/post/24490758395/loading-half-a-billion-rows-into-mysql and fired up the same command
time python load.py -D test -P 3307real 536m0.376s
user 27m17.130s
sys 5m36.780s
I did not disable indexes for this run to make it fair compared to SingleStore.
Conclusion
With the Peak Hosting offering of 512Gb of RAM and memory optimized software like SingleStore you can save full business days in data loading and get immediate, valuable insight into your data.





