Want to try SingleStoreDB Self-Managed 6? Click here to get started. Prefer the Release Notes? They are here.
Today marks another milestone for SingleStore as we share the details of our latest release, SingleStoreDB Self-Managed 6. This release encapsulates over one year of extensive development to continue making SingleStore the best database platform for real-time analytics with a focus on real-time data warehouse use cases.
Additionally, SingleStoreDB Self-Managed 6 brings a range of new machine learning capabilities to SingleStore, closing the gap between data science and operational applications.
Product Pillars
SingleStoreDB Self-Managed 6 has three foundational pillars:
- Extensibility
- Query Performance
- Enhanced Online Operations
Let’s explore each of these in detail.
Extensibility
Extensibility covers the world of stored procedures, user defined functions (UDFs), and user defined aggregates (UDAs). Together these capabilities represent a mechanism for SingleStore to offer in-database functions that provide powerful custom processing.
For those familiar with other databases, you may know of PL/SQL (Procedural Language/Structured Query Language) developed by Oracle, or T-SQL (Transact-SQL) jointly developed by Sybase and Microsoft. SingleStore has developed its own approach to offering similar functions with MPSQL (Massively Parallel Structured Query Language).
MPSQL takes advantage of the new code generation that was implemented in SingleStoreDB Self-Managed 5. Essentially we are able to use that code generation to compile MPSQL functions. Specifically we implement native machine code for stored procedures, UDFs, and UDAs in-lined into the compiled code that we generate for a query.
Long story short, we expect MPSQL to provide a level of peak performance not previously seen with other databases’ custom functions.
SingleStore extensibility functions are also aware of our distributed system architecture. This innovation allows for custom functions to be executed in parallel across a distributed system, further enhancing overall performance.
Benefits of extensibility include the ability to centralized processes in the database across multiple applications, the performance of embedded functions, and the potential to create new machine learning functions as detailed later in this post.
Query Processing Performance
SingleStoreDB Self-Managed 6 includes breakthrough improvements in query processing. One area is through operations on encoded data. SingleStoreDB Self-Managed 6 includes dictionary encoding, which can translate data into highly compressed unique values that can then be used to conduct incredibly fast scans.
Consider the example of a public dataset about every airline flight in the United States from 1987 until 2015, as outlined in our blog post Delivering Scalable Self Service Analytics.
With this dataset SingleStore can encode and compress the data, allowing for extremely rapid scans of up to 1 billion rows per second per core.
SingleStoreDB Self-Managed 6 also makes use of improvements to the Intel advancements with Single Instruction, Multiple Data (SIMD). This technique allows the CPU to complete multiple data operations in a single instruction, essentially vectorizing and parallel processing the query.
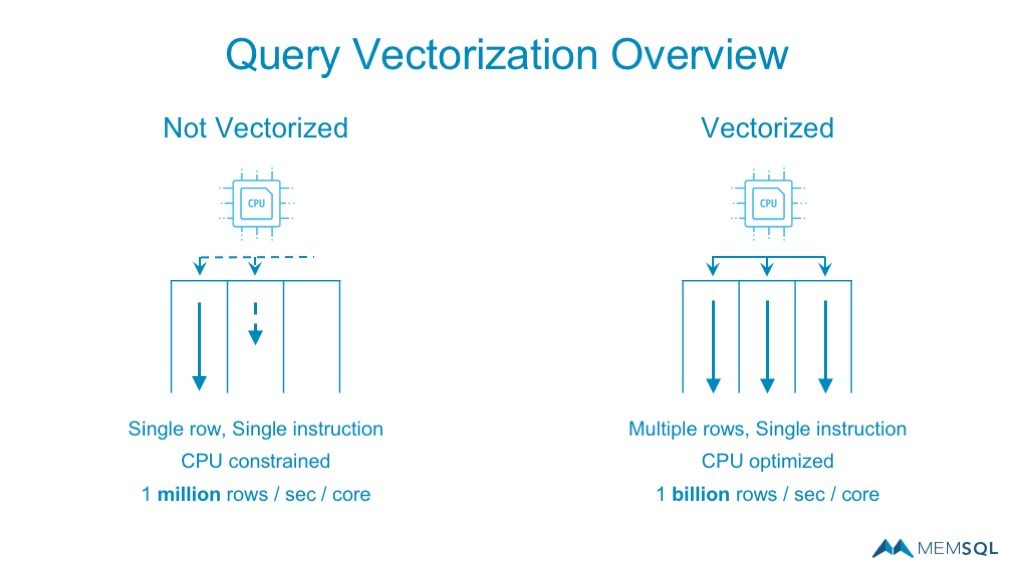
The benefits of these query processing advancements include having a detailed data view without needing to pre-process the data. This further allows for interactive analysis on raw, unaggregated data, providing the most up-to-date and accurate query results possible.
Enhanced Online Operations
To power mission critical applications, data platforms must be online all the time, and with SingleStoreDB Self-Managed 6 we have enhanced our ability for SingleStore to operate online. The benefits of these improvements include more sophisticated monitoring and recovery, easier application development, and improved overall availability.
Machine Learning and SingleStoreDB Self-Managed 6
SingleStoreDB Self-Managed 6 helps close the gap between machine learning and operational applications in three areas:
- Built-in machine learning functions
- Real-time machine learning scoring
- Machine learning in SQL with extensibility
Built-in Machine Learning Functions
SingleStoreDB Self-Managed 6 includes new machine learning functions like DOT_PRODUCT, which can be used for real-time image recognition but also for any application requiring the comparison of two vectors. While this function itself is not new in the world of machine learning, SingleStore now delivers this function within its distributed SQL database, enabling an unprecedented level of performance and scale.
For more information, check out this blog post, An Engineering View on Real-Time Time Machine Learning.
Real-Time Machine Learning Scoring
SingleStore includes the ability to manage real-time data pipelines with custom transformations at ingest. This transformation can also deliver the execution and scoring using a machine learning model. For example, you may choose to take a machine learning model from SAS and export it using PMML, the predictive modeling markup language.
This allows real-time scoring on ingest and co-locating the raw data and the instant score next to each other in the same row in the same table. This simple structure, sets a foundation for easy predictive analytics.
Enabling Machine Learning in SQL with Extensibility
The new SingleStore extensibility functions also enable a new approach to machine learning directly in SQL. This can dramatically shorten the gap between data science and production applications as operations occur on the live data, and models can be trained and updated to incorporate and reflect the most recent data.
We recently showcased an example of this with k-means clustering by simply using native SQL and SingleStore. You can see the presentation here on Slideshare.
Taking Machine Learning Real-Time
With the new features of SingleStoreDB Self-Managed 6 including extensibility and query performance, we expect more machine learning applications to incorporate SingleStore as the persistent data store.
The SingleStore architecture is well suited to work in conjunction with other machine learning systems, and real-time data pipelines. For example, SingleStore includes:
- A distributed, scale out architecture well suited to performance and large scale workloads
- An open source SingleStore Spark Connector for high-throughput, highly-parallel, and bidirectional connectivity to Spark
- Native integration with Kafka message queues including the ability to support exactly-once semantics
- Full transactional SQL semantics so you can build production applications for the front lines of your business
Together, we see these capabilities as foundational for real-time machine learning workloads, and we invite you to try the latest version of SingleStore today at singlestore.com/cloud-trial/.





