Setting the Stage for Spark
With Spark on track to replace MapReduce, enterprises are flocking to the open source framework in effort to take advantage of its superior distributed data processing power.
IT leads that manage infrastructure and data pipelines of high-traffic websites are running Spark–in particular, Spark Streaming which is ideal for structuring real-time data on the fly–to reliably capture and process event data, and write it in a format that can immediately be queried by analysts.
As the world’s premiere visual bookmarking tool, Pinterest is one of the innovative organizations taking advantage of Spark. Pinterest found a natural fit in SingleStore’s in-memory database and Spark Streaming, and is using these tools to find patterns in high-value user engagement data.
Pinterest’s Spark Streaming Setup
Here’s how it works:
- Pinterest pushes event data, such as pins and repins, to Apache Kafka.
- Spark Streaming ingests event data from Apache Kafka, then filters by event type and enriches each event with full pin and geo-location data.
- Using the SingleStore Spark Connector, data is then written to SingleStore with each event type flowing into a separate table. SingleStore handles record deduplication (Kafka’s “at least once” semantics guarantee fault tolerance but not uniqueness).
- As data is streaming in, Pinterest is able to run queries in SingleStore to generate engagement metrics and report on various event data like pins, repins, comments and logins.
Visualizing the Data
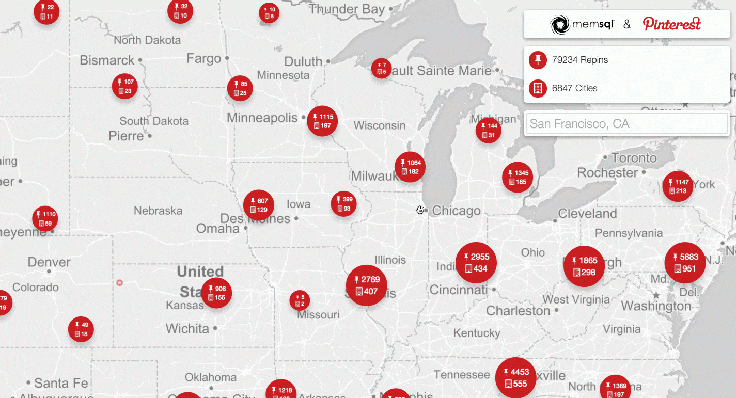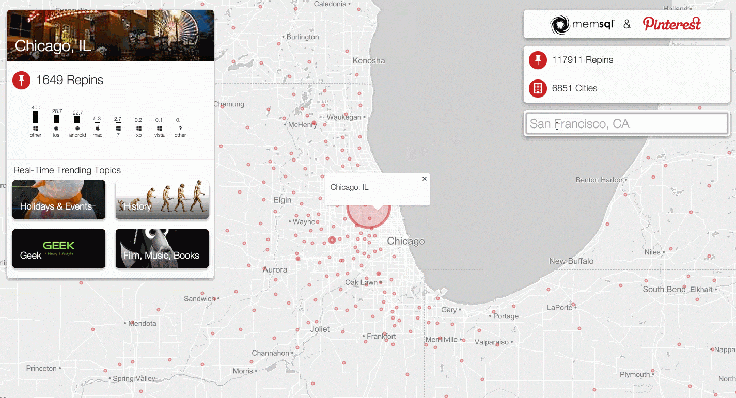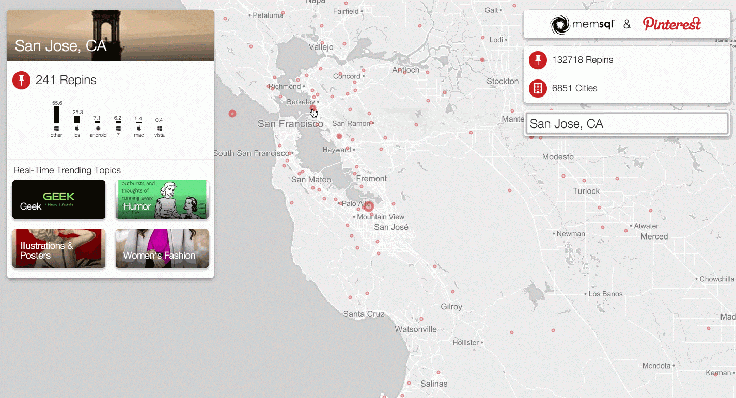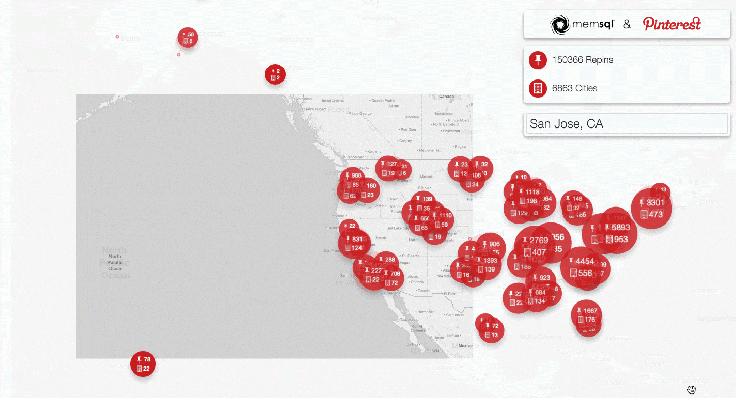
We built a demo with Pinterest to showcase the locations of repins as they happen. When an image is repinned, circles on the globe expand, providing a visual representation of the concentration of repins by location.
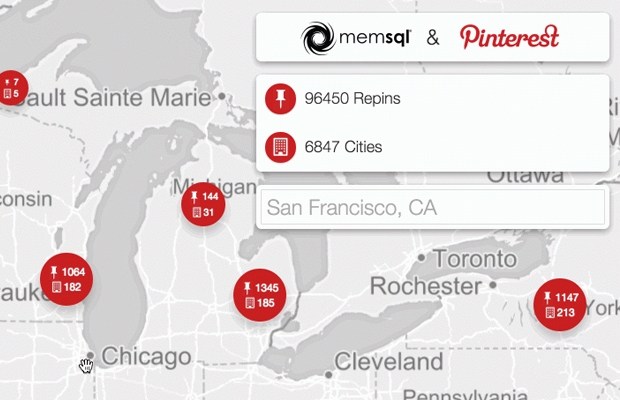
The demo also leverages Spark to enrich streaming data with geolocation information between the time that it arrives and when it hits the database. SingleStore adds to this enrichment process by serving as a key/value cache for data that has already been processed and can be reused for future repins. Additionally, as part of the enrichment process, any repin that enters the system is looked up against SingleStore, and is saved to SingleStore if the full pin is missing. All full pins that come in through the stream are saved automatically to avoid this lookup.
Pinterest showcases real-time user engagement across the globe using @SingleStoreDB and @apachespark – Click to Tweet
So, What’s the Point?
This infrastructure gives Pinterest the ability to identify (and react to) developing trends as they happen. In turn, Pinterest and their partners can get a better understanding of user behavior and provide more value to the Pinner community. Because everything SQL based, access to data is more widespread. Engineers and analyst can work with familiar tools to run queries and track high-value user activity such as repins.
It also should be noted that this Spark initiative is just the beginning for Pinterest. As the Spark framework evolves and the community continues to grow, Pinterest expects to expand use cases for SingleStore and Spark.
Initial Results
After integrating Spark Streaming and SingleStore, running on AWS, into their data stack, Pinterest now has a source of record for sharing relevant user engagement data and metrics their data analyst and with key brands.
With SingleStore and Spark, Pinterest has found a method for repeatable, production-ready streaming and is able to go from pipe dump to graph in real time.
Get The SingleStore Spark Connector Guide
The 79 page guide covers how to design, build, and deploy Spark applications using the SingleStore Spark Connector. Inside, you will find code samples to help you get started and performance recommendations for your production-ready Apache Spark and SingleStore implementations.
Download Here




