
SingleStore Streamliner, an open source tool available on GitHub, is an integrated solution for building real-time data pipelines using Apache Spark. With Streamliner, you can stream data from real-time data sources (e.g. Apache Kafka), perform data transformations within Apache Spark, and ultimately load data into SingleStore for persistence and application serving.
Streamliner is great tool for developers and data scientists since little to no code is required – users can instantly build their pipelines.
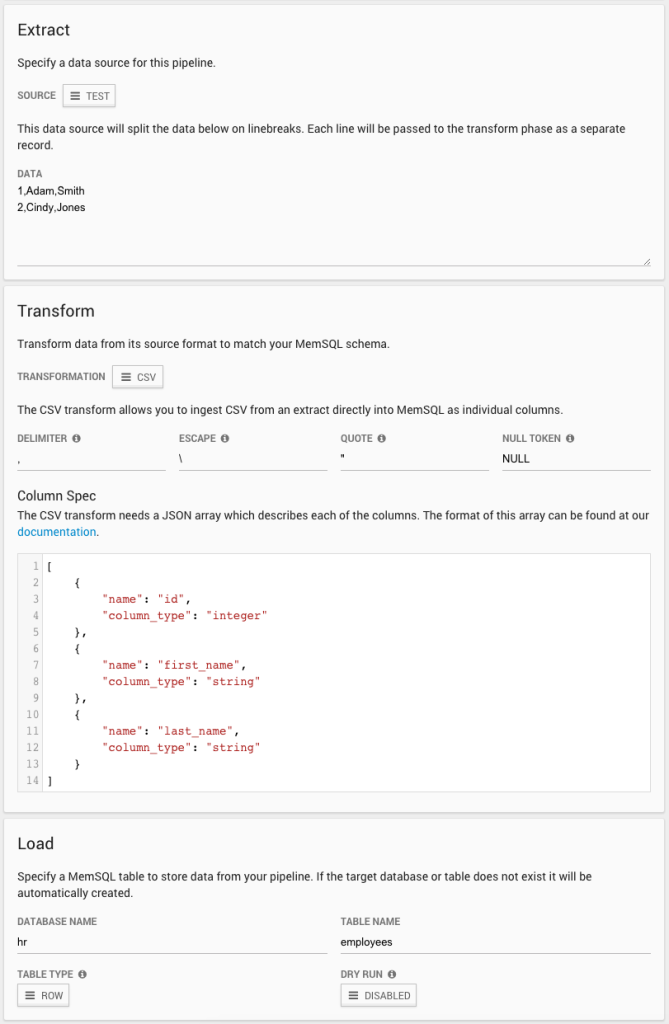
For instance, a non-trivial yet still no-code-required use case is: pulling data in a comma-separated value (CSV) format from a real-time data source; parsing it; then creating and populating a SingleStore table. You can do all this within the Ops web UI, depicted in the image below.
As you can see, we have simulated the real-time data source with a “Test” that feeds in static CSV values. You can easily replace that with Kafka or a custom data source. The static data is then loaded into the hr.employees table in SingleStore.
Sometimes, however, you need to perform more complex operations on your data before inserting it into SingleStore. Streamliner supports uploading JAR files containing your own Extractor and Transformer classes, allowing you to run extracts from custom data sources and arbitrary transformations on your data.
Here is an example of how to create a custom Transformer class. It assumes we will receive strings from an input source (e.g. Kafka) that represent user IDs and their country of origin. For each user, we are going to look up the capital of their country and write out their user ID, country, and capital to SingleStore.
The first thing you should do is check out the Streamliner starter repo on GitHub. This repo is a barebones template that contains everything you need to start writing code for your own Streamliner pipelines.
Our example Transformer is going to have a map from ISO country code to that country’s capital. It takes in a CSV string containing a user ID (which is an integer) and a country code. It will return a DataFrame containing rows with three columns: user ID, country code, and country capital.
Open up Transformers.scala and edit the BasicTransformer code so that it looks like this:
class BasicTransformer extends SimpleByteArrayTransformer{val countryCodeToCapital = Map(
"AD" -> "Andorra la Vella",
"AE" -> "Abu Dhabi",
"AF" -> "Kabul",
"AG" -> "St. John's",
… // You may add as many entries as you’d like to this map.
)
override def transform(sqlContext: SQLContext, rdd: RDD[Array[Byte]], config: UserTransformConfig, logger: PhaseLogger): DataFrame ={val rowRDD = rdd.map(x =>{val fields = byteUtils.bytesToUTF8String(x).split(',')
val userId = fields(0).toLong
val countryCode = fields(1)
val capital: String = countryCodeToCapital.getOrElse(countryCode, null)
Row(userId, countryCode, capital)} )
val schema = StructType(Array(
StructField("user_id", LongType, true),
StructField("country_code", StringType, true),
StructField("capital", StringType, true)
))
sqlContext.createDataFrame(rowRDD, schema)} } 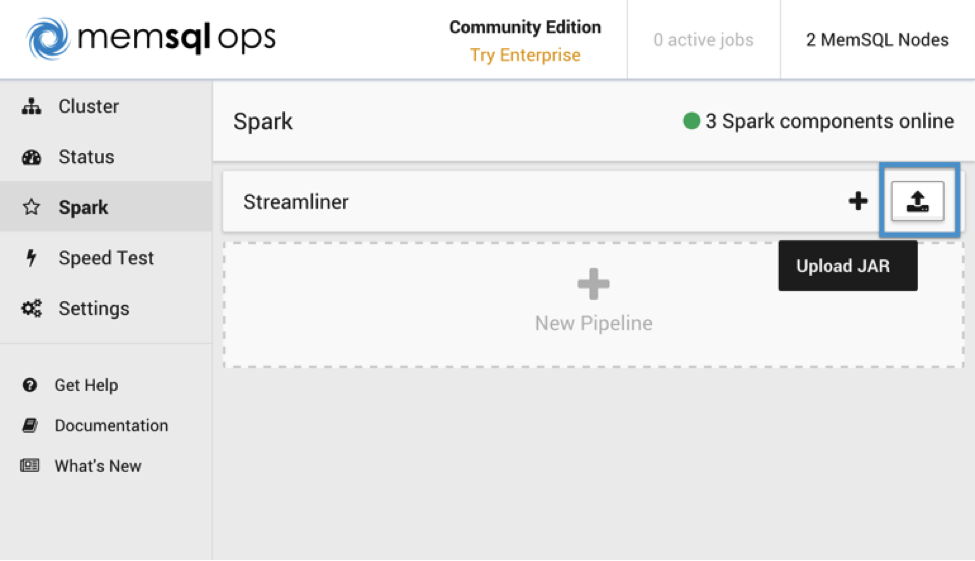
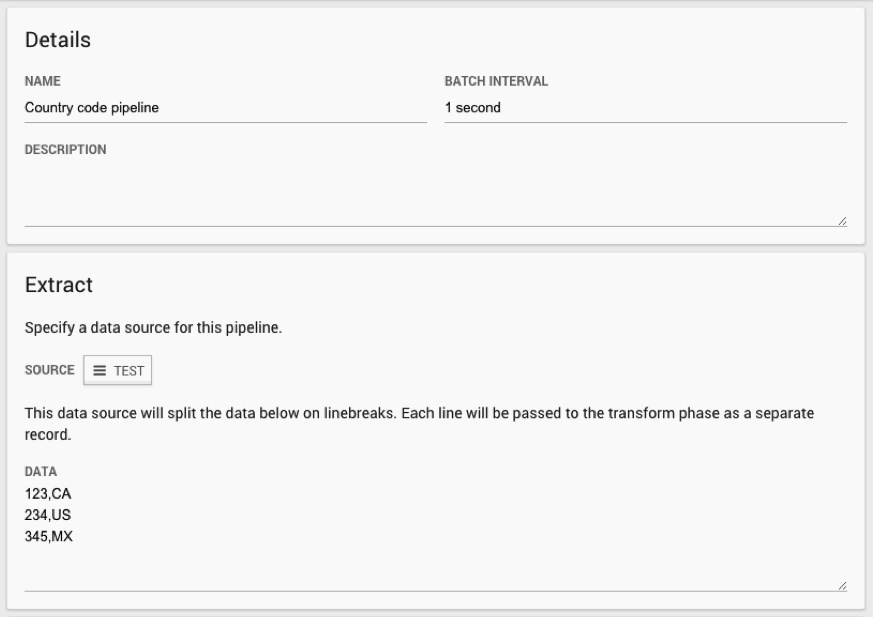
Then create a new pipeline. For now, we will use the test extractor, which sends a constant stream of strings to our transformer; this is very useful for testing your code.
Then, choose your BasicTransformer class.
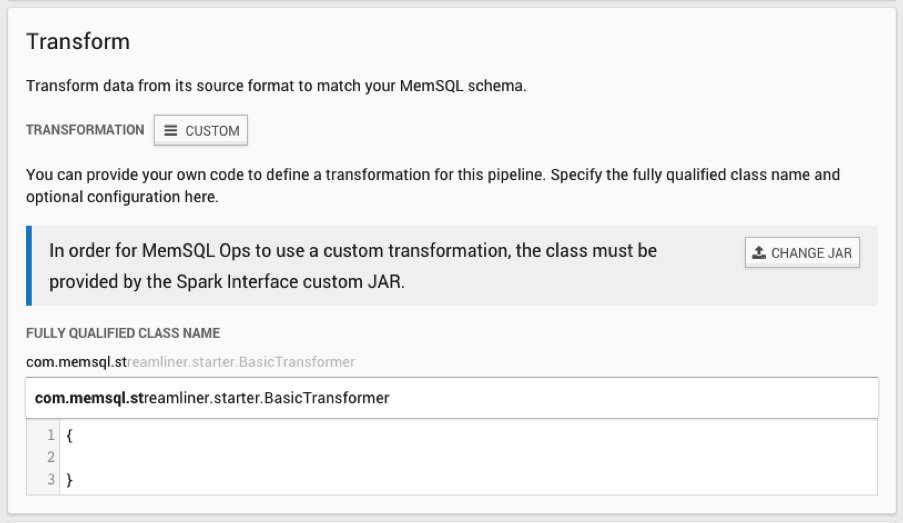
Finally, choose the database and table name in SingleStore where you would like your data to go.
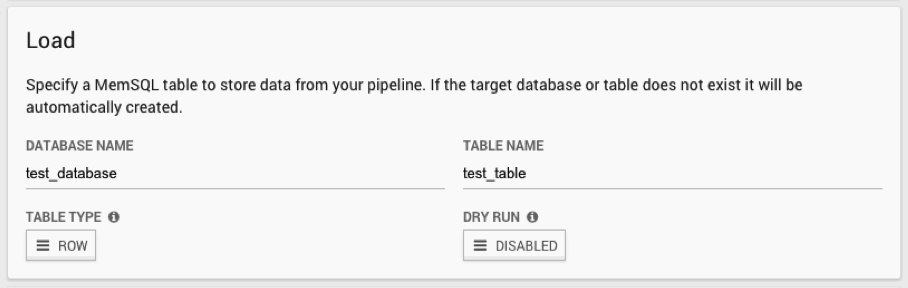
Once you save your pipeline, it will automatically start running and populating your table with data.
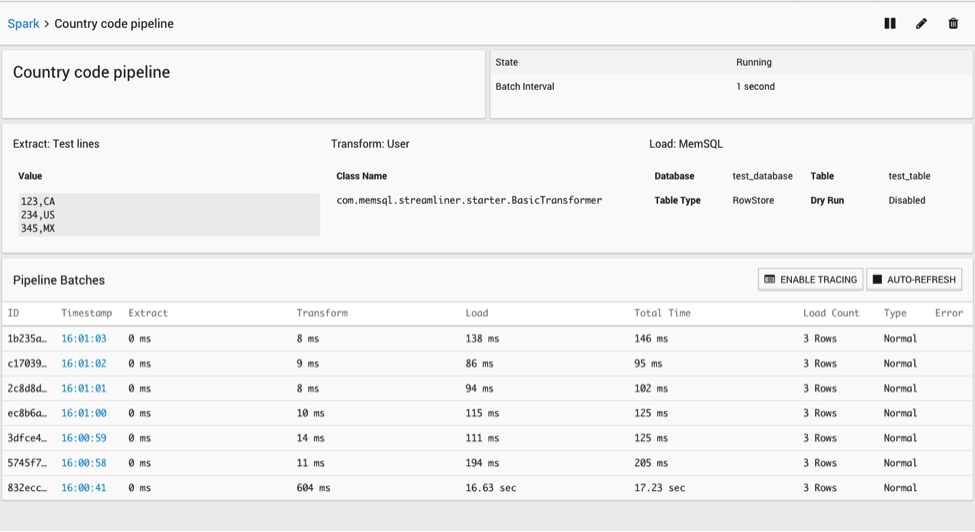
You can select rows from the table created in SingleStore to see that it is being populated with your transformed data:
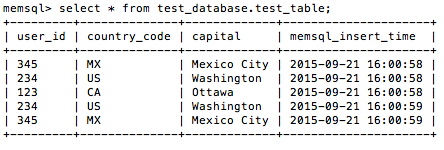
Writing your own transformers is an extremely powerful way to manipulate data in real-time pipelines. The code shown above is just one demonstration of how Streamliner gives you the ability to easily pre-process data while leveraging the power of Spark – a fast, general purpose, distributed framework. Check out the SingleStore documentation and the Streamliner examples repo for more examples of the kinds of things you can do with Streamliner.





