
Take a look at your database. What do you see? An alphabetic list of table names. Is that really the most important thing to know? Surely, other facts about your database are more interesting. Maybe you want to know how big the tables are.
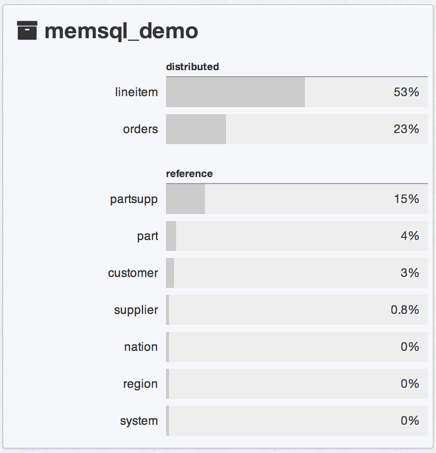
Database table sizes, like mountain heights and city populations and book sales, tend to follow a pattern casually called a power-law distribution. A minority of tables hold the majority of data. The rest are a long tail of necessary but small things, a kind of embroidery around the edges. Below is a more meaningful list of tables, sorted by the space they consume.
Does the pattern stop there? Look at your tables. Not just the columns, but what’s in them. The schema tells you that the “title” column is in the 5th position. It’s a varchar that can go up to 64 characters… or it might be blank. Or NULL.

In a just world, blank values would be a rare corner case, a placeholder for the occasional missing datum. Tables would be an endless stream of rows of identical structure, with a place for every bit and every bit in its place. But it just ain’t so. Blank values crop up a lot more often than we’d like because the data we shove into tables is not really tabular. The attributes of real-world things, the columns in your tables, exhibit the same lopsided power-law distribution. There will always be more first names than middle names, and more middle names than suffixes like “Junior”.
“Reality is that which, when you stop believing in it, doesn’t go away.”
— Philip K Dick
Over time this “persons” table evolves into the usual 100-column string soup. There will be dozens of long-tail attributes that are important but rare: previous_nationality, maiden_name, or passport_number. Adding support for those attributes means reserving a blank spot for every row where it does not and will never apply. After years of attempting to encompass messy reality with a rigid grid, the table becomes mostly air. Dealing with some missing values is one thing. Dealing with so many thinly-populated dimensions is something else entirely.
Plot the Pain
It’s straightforward to plot sparseness using standard SQL. A handy feature of the count() function is that it ignores NULLs. To count columns that have a default value, you can sum over a boolean expression. I’ll bet money that your biggest tables have a large number of mostly-empty columns and small set of core columns, just like this example.
memsql> select
count(id)/count(1) as id,
sum(first_name != '')/count(1) as first,
count(maiden_name)/count(1) as maiden,
...
sum(passport_num != 0)/count(1) as passport
from persons;
+--------+--------+--------+ +------------+
| id | first | maiden | ... | passport |
+--------+--------+--------+ +------------+
| 1.0000 | 0.9984 | 0.1270 | ... | 0.0942 |
+--------+--------+--------+ +------------+
You can also plot the sparseness horizontally to get a sense of how many columns are actually used on average. There may be 100 possible columns in this table but only about 20 are needed at a given time.
memsql> select
used_column_count,
format(count(1),0) as cnt
from (
select
(id is not null) +
(first_name != '') +
(maiden_name is not null) +
...
(passport_num != 0) as used_column_count
from persons
) as tmp
group by 1
order by 2 desc;
+-------------------+------------+
| used_column_count | cnt |
+-------------------+------------+
| 21 | 11,090,871 |
| 20 | 2,430,207 |
| 14 | 319,891 |
| 19 | 11,766 |
| 25 | 2,725 |
| 17 | 499 |
| 18 | 303 |
...
The most obvious problem is managing the storage for huge sparse tables. An “empty” cell still consumes space. Repeated values compress nicely, but you’re not always dealing with compressed data. And high compressibility only underscores the fact that there’s not much information there to begin with.
A bigger problem is that the harder it is to add / move / delete columns, the more conservative you are about doing it. The overhead and operational pain of adding columns to support the features you write is only the visible cost. What about all the long-tail features you don’t write, or even let yourself think about, because altering a big table in traditional SQL databases is so traumatic?
Consider Your Options
There are several ways to deal with the sparseness of the world around us. You can rearrange your schema, maybe factor out that address table, but essentially continue to treat sparseness as one of the miseries of life. You can read up on the Fourth Normal Form and slice your tables into lots of thin vertical strips, but that presents obvious practical problems. You can switch to a “NoSQL” system that promises more flexibility, but blaming the syntax has never made sense to me. SQL is not the problem, nor is your schema. The implementation underneath is what matters. There is nothing inherent in SQL that prevents it from adding columns and indexes without locking the table, or otherwise handling sparse dimensions gracefully.
“There are only two kinds of languages: the ones people complain about and the ones nobody uses.”
— Bjarne Stroustrup
Say what you want about SQL, but it’s a pretty good language for manipulating data. It’s suspiciously difficult to design a new relational query language that doesn’t come to resemble it. In the ruthless, amnesiac world of technology, anything that’s been thriving for 40 years is probably doing something right.
A pragmatic option for sparse data is to use a SQL database with a native JSON column type. That buys you sets, maps, lists, trees, and any combination. Adding a new attribute is as simple as writing new keys and values, no schema changes needed. But you can still use them in queries as you would normal columns. More to the point, those optional keys and values can live right next to the dense ones. It doesn’t have to be either/or.
A few relational databases support JSON natively now, including SingleStore. You can store JSON as plain strings in any database, of course. Or serialized Python objects for that matter. But native support helps you find a middle ground between the constraints of fixed table schemas and turning your database into a glorified key/value store. The relational set operations at the core of your application have to happen somewhere, so why not let the database do what it was designed to do?
For a table like this you’ll want to keep the dense attributes (say, anything over 30% full) as first-class typed columns. The sparse stuff goes into a JSON blob in the same table.
create table persons (
id bigint unsigned primary key,
first_name varchar(64) not null default '',
last_name varchar(64) not null default '',
--- 10 more dense columns...
opt JSON not null
);
The structure of your queries hardly changes at all. Instead of filtering on sparse columns like this:
WHERE maiden_name like '%jingleheimer-schmidt%'
You do it like this:
WHERE opt::$maiden_name like '%jingleheimer-schmidt%'
If later on an optional column becomes heavily used, you can simply hoist it up to a first-class column and add an index:
memsql> alter online table persons add column middle_name
as opt::$middle_name persisted varchar(64);
memsql> alter online table persons add key (middle_name);
…and start using it right away. Your production SingleStore database won’t miss a beat. This hybrid table model is an effective way to handle the sparseness you can’t avoid and shouldn’t let get in your way. It saves space, time, and energy you can apply to more important things.





