
In today’s wave of Enterprise Cloud applications, having trust in a data store behind your software-as-a-service (SaaS) application is a must. Thus, multi-tenancy support is a critical feature for any enterprise-grade database. This blog post will cover the ways to implement multi-tenancy, and best practices for doing so in SingleStore.
As customer table sizes grow, you will need to scale out your multi-tenant database across dozens of machines. To support rich analytics about your customers or as a feature for your end customers, you will want a solution that scales without bogging down reporting capabilities. Successful multi-tenant platforms require massive scalability, online patching/upgrading, the ability to process high volumes of data ingestion, and deliver high performing complex analytics.
SingleStore delivers the requirements for a multi-tenant platform through the rich analytical and transactions capabilities of SQL. SingleStore also scales to hundreds of nodes in a cluster leveraging shared nothing commodity hardware. Combining these multi-tenant capabilities with extreme data ingestion makes SingleStore a truly unique product to deliver SaaS data.
Most database architectural patterns for multi-tenant applications follow one of three approaches:
- Separated Database
- Separate Schema
- Shared Schema
If isolation requirements are not accounted for early in application development, retrofitting them can be even more costly. In our conversations with customers, scale is often the driver. Let’s delve into the three models:
1) Separated Database
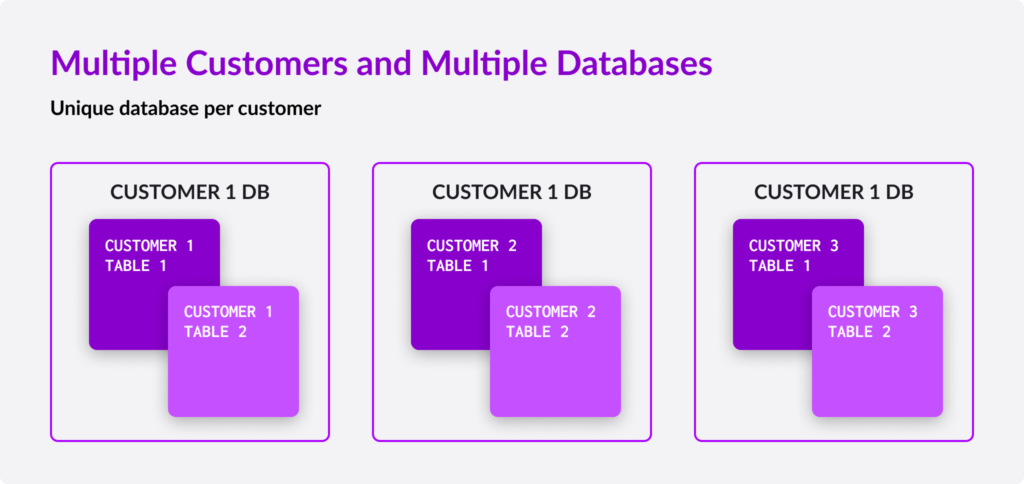
Instantiating each tenant as its own database in SingleStore is a practical idea for data isolation guarantees. However, if you plan to scale past 50-100 tenants, spinning up a new database instance for each tenant will increase maintenance cost.
While former SaaS applications make good use of separate database instances, scaling a software business in the cloud necessitates alternative solutions. With the database-per-tenant model, there are costs related to increased cloud resource sharing as well as maintaining and managing many databases. For example, you would probably need different backup strategies per tenant. SaaS application developers often struggle when making such trade-offs. Lastly, performing analytics across your customer base would result in relatively complex multi-database queries.
2) Separate Schema
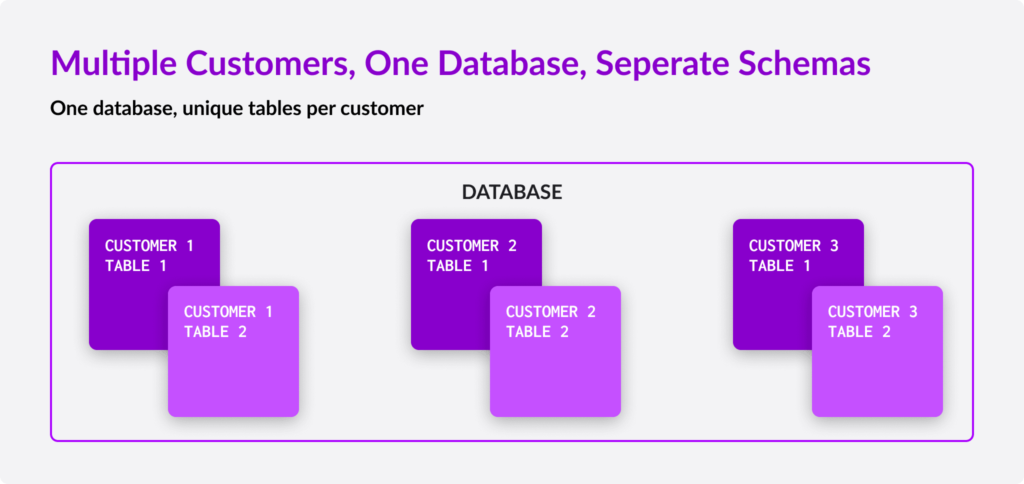
Keeping your data isolated logically, but in different table schemas, can be a beneficial strategy. With the “separate schema” approach, your tenant’s’ data is just as separated logically, but within the same database for less maintenance headaches or overhead. Backups are done in full, for all tenants at once.
Role-Based Access Control (RBAC) can be used to keep your tenants’ data protected. See an example below of giving user permissions to tables by named TENANTID:
CREATE DATABASE app;
CREATE TABLE <TENANTID>.table1;
CREATE ROLE 'app_<TENANTID>_schema_role';
GRANT SELECT, INSERT, UPDATE, DELETE on <TENANTID> to ROLE 'app_<TENANTID>_schema_role';
GRANT SHOW VIEW on <TENANTID> to ROLE 'app_<TENANTID>_schema_role';
GRANT CREATE TEMPORARY TABLES on <TENANTID> to ROLE 'app_<TENANTID>_schema_role';
CREATE GROUP '<TENANTID>_users';
GRANT ROLE 'app_<TENANTID>_schema_role' to '<TENANTID>_users';
GRANT USAGE on <TENANTID> to 'user_1' IDENTIFIED BY 'abc';
GRANT GROUP '<TENANTID>_users' to 'user_1';
This example can be extended to any number of users or user groups for any tenant.
Taking a Separate Schema approach has additional benefits. Since everything is inside the same logical database, hardware resources are equally shared among tenants, saving costs. Table schemas used can be different per customer, which allows you to customize a specific tenant without affecting others.
3) Shared Schema
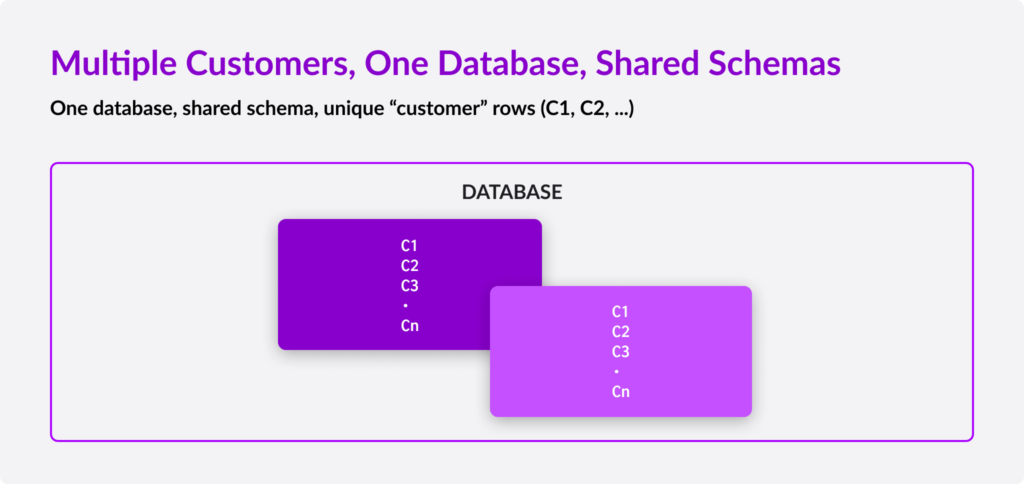
In the Shared Schema model, everything is shared – server, database, and tables. All data for your tenants are within the same table(s) in one logical database. A “TenantId” column can be used on the table to differentiate each row of data, and you can use this as your shard key in SingleStore to ensure that all data for a given tenant lies on the same physical machine.
In addition to RBAC, SingleStore allows you to architect for this model with Row-Level Security (RLS). Presuming that all data for all tenants is stored in one table, user roles are created for each tenant’s subset of the data as such:
UPDATE <table> SET ACCESS_ROLES=CONCAT(ACCESS_ROLES, "ROLE,") WHERE ID=<TENANTID>;
Given the instantiated tenant roles above, you can implement customer views.
CREATE VIEW <view_name> AS SELECT COLUMNS FROM <table> WHERE SECURITY_LISTS_INTERSECT(CURRENT_ROLES(), ACCESS_ROLES);
Another big benefit is code changes: with this model, schema changes become painless as you only have one spot to change code (i.e. table structure). With the other options you would have to roll out code changes to many spots.
Finally, you may wish to create reports to aggregate tenant data. In the “Separated Database” model, global reporting of customer data becomes onerous.100 customers in 100 unique databases each with a clickstream table, for example, means you would have to do a 100 table cross-database union all join to provide global reporting of all customers. In practice, you would have to build an extraction process to a data warehouse to consolidate, but now there’s significant ETL to contend with. You could roll up per customer, but now you still have to send the aggregate data to one place and trust it’s accurate as well as recent. With the “Shared Schema” or “Separate Schema” models this is an achievable task.
Starting with SingleStoreDB Self-Managed 6.0, you can create a stored procedure to calculate and rollup data for each tenant (or even across tenants). See www.singlestore.com/managed-service/ for more information.
SingleStore delivers what multitenant platforms require: massive scalability, online patching/upgrading, the ability to process high volumes of data ingestion and deliver high performing complex analytics on rapidly changing data.
As more SaaS application providers push for scalable data warehouse solutions in the cloud, isolation of data and cost of storage are paramount to a multi-tenant environment. There are various ways to design for multi-tenancy, and there are always tradeoffs to be made for each case. With its robust security functionality and distributed scale-out performance, SingleStore can fit any model you choose. Give it a try by visiting www.singlestore.com/cloud-trial/.





