
Adaptation and Reinvention
Long term success hinges on adaptation and reinvention, especially in our dynamic world where nothing lasts forever. Especially with business, we routinely see the rise and fall of products and companies.
The long game mandates change, and the database ecosystem is no different. Today, megatrends of social, mobile, cloud, big data, analytics, IoT, and machine learning place us at a generational intersection.
Data drives our digital world and the systems that shepherd it underpin much of our technology infrastructure. But data systems are morphing rapidly, and companies reliant on data infrastructure must keep pace with change. In other words, winning companies will need to jump the database S-Curve.
The S-Curve Concept
In 2011, Paul Nunes and Tim Breene of the Accenture Institute for High Performance published Jumping the S-curve: How to Beat the Growth Cycle, Get on Top, and Stay There.
In the world of innovation, an S-curve explains the common evolution of a successful new technology or product. At first, early adopters provide the momentum behind uptake. A steep ascent follows, as the masses swiftly catch up. Finally, the curve levels off sharply, as the adoption approaches saturation.
The book details a common dilemma that too many businesses only manage to a single S-curve of revenue growth,
in which a business starts out slowly, grows rapidly until it approaches market saturation, and then levels off.
They share the contrast of stand-out, high-performance businesses that manage growth across multiple S-curves. These companies continually find ways to invent new products and services that drive long term revenue and efficiency.
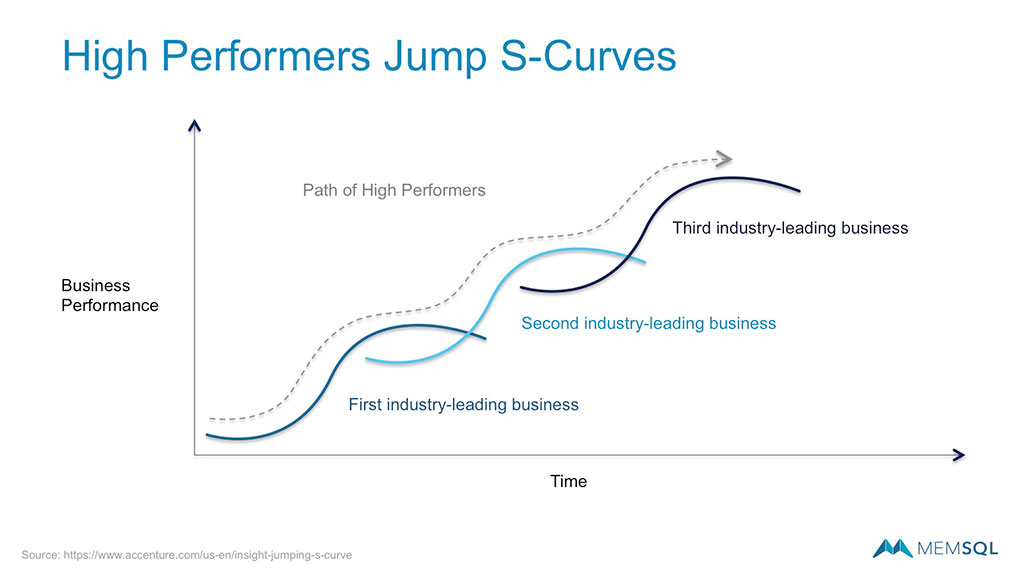
Authors Nunes and Breene outline three traits of high-performance companies that successfully scale multiple S-curves,
- A Big Enough Market Insight
Companies must identify, “a substantial market change on the horizon that heralds the chance to build a major business for the company that identifies and seizes the opportunity.” - Threshold Competence Before Scaling
Companies “understand exactly how they must be distinctive in order to create the value the market demands.” - Worthy of Serious Talent
“High performers attract and keep the ‘serious talent’ they need—the people with the abilities and the attitude to drive the creation of successful businesses.”
Applying the S-Curve to Data Infrastructure
The S-Curve applies to new technologies and products, and for the rest of this piece, we apply the concept to the evolving database and data management world.
The Monolithic Era
The initial era of databases and data warehouses tracked the path of monolithic, single node, scale up systems. As CPU, memory, and storage density increased, data volumes and performance requirements were typically satisfied by a single server’s capabilities. Over time this expanded to very expensive servers and often more expensive storage area networks (SANs).
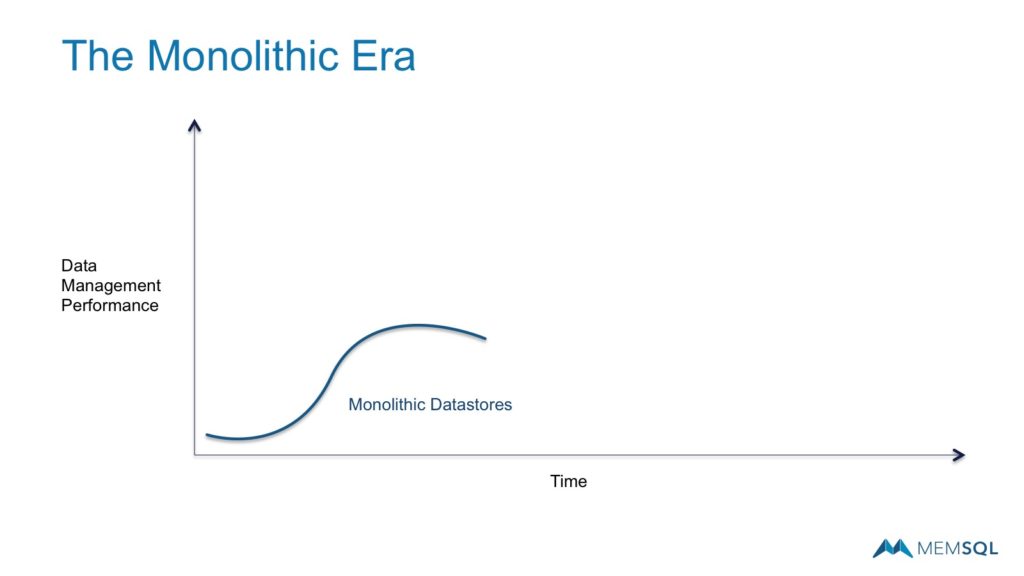
Architects recognized the simplicity of single server systems, and the advantages provided to build robust architectures for mission critical applications.
For most of the last thirty to forty years, since the development of SQL in the 1970s, this model served the industry well.
However, when data volumes and performance requirements increased dramatically, as we see with digital megatrends, the limits of a single server system become readily apparent.
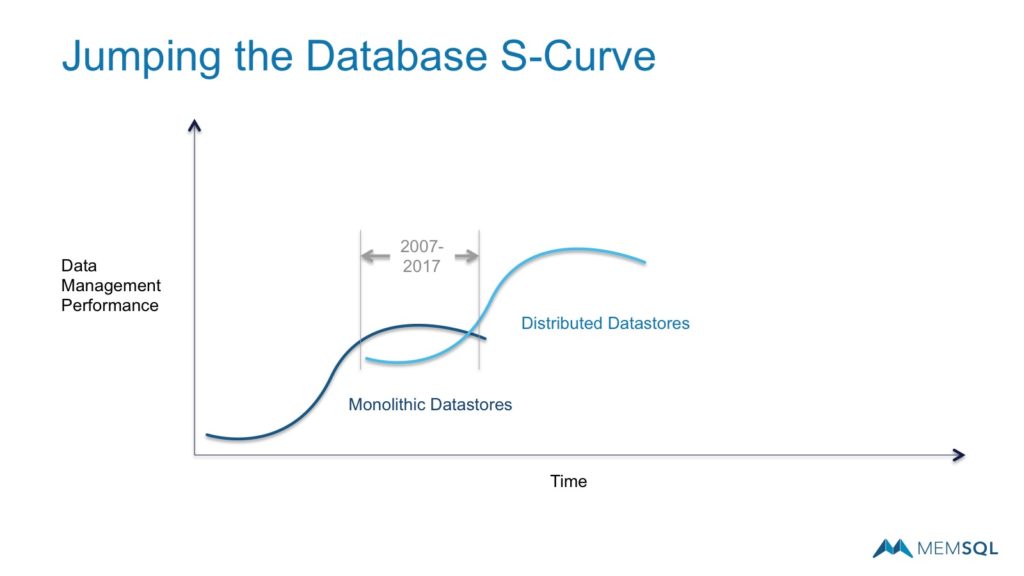
The Distributed Era
Starting around 2007, distributed datastores like Hadoop began to take hold. Distributed architectures use clusters of low-cost servers in concert to achieve scale and economic efficiencies not possible with monolithic systems. In the past ten years, a range of distributed systems have emerged to power a new S-Curve of business progress.
Examples of prominent technologies in the distributed era include, but are certainly not limited to
- Message queues like Apache Kafka and AWS Kinesis
- Transformation tiers like Apache Spark
- Orchestration systems like Zookeeper and Kubernetes
More specifically in the datastore arena are
- Key-value stores like Cassandra
- Document stores like MongoDB
- Relational datastores like SingleStore
Advantages of Distributed Datastores
Distributed datastores provide numerous advantages over monolithic systems, including
- Scale – aggregating servers together enables larger capacities than single node systems
- Performance – the power of many far outpaces the power of one
- Alignment with CPU trends – while CPUs are gaining more cores, processing power per core has not grown nearly as much. Distributed systems are designed from the start to scale out to more CPUs and cores
Numerous economic efficiencies also come into play with distributed datastores, including
- No SANs – distributed systems can store data locally to make use of low-cost server resources
- No sharding – scaling monolithic systems requires attention to sharding. Distributed system remove this need
- Deployment flexibility – well designed distributed systems will run across bare metal, containers, virtual machines, and the cloud
- Common core team for numerous configurations – with one type of distributed system, IT teams can configure a range of clusters for different capacities and performance requirements
- Industry standard servers – low cost hardware or cloud instances provide ample resources for distributed systems. No appliances required
Together these architectural and economic advantages mark the rationale for jumping the Database S-Curve.
The Future of AI Augmented Datastores
Beyond distributed datastores, the future includes more artificial intelligence (AI) and using it to streamline data management performance.
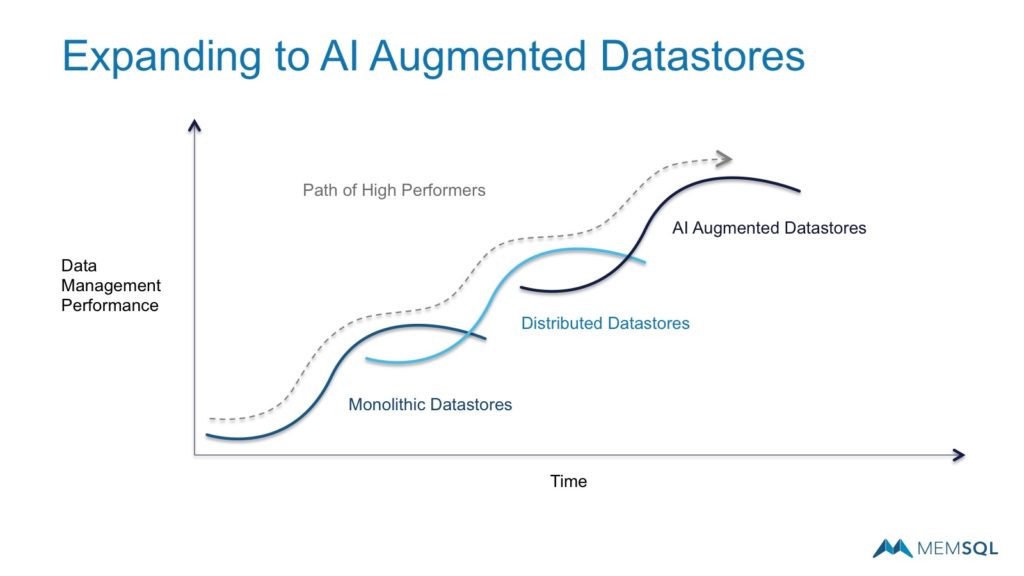
AI will appear in many ways, including
Natural Language Queries – such as sophisticated queries expressed in business terminology using voice recognition
Efficient Data Storage – by identifying more logical patterns, compressing effectively, and creating indexes without requiring a trained database administrator
New Pattern Recognition – discerning new trends in the data without the user having to specify a query
Of course, AI will likely expand data management performance far beyond these examples too. In fact, in a recent news release Gartner predicts,
More than 40 percent of data science tasks will be automated by 2020, resulting in increased productivity and broader usage of data and analytics by citizen data scientists
Transcending Database S-Curves
The industry currently sits at the intersection of the monolithic and the distributed datastore eras, and jumping S-Curves is no easy feat. By definition, a new S-Curve is significantly different from the prior, where many technologies, skill sets, and mindsets likely do not transfer forward.
Addressing this transformation, Paul Nunes advises,
Pay attention to insights that arise from the periphery of the organization
Perhaps Nunes is suggesting successful companies have the talent and mindset needed to jump, but need to be creative to discover it.
Adopting new products and technologies mandates change, which is rarely easy and often challenging at first. But if there is one universal truth about business, staying in place rarely leads to long term success. Companies that move forward however, have a chance to jump the S-Curve and lead another wave of growth.





