Apache Spark is one of the most powerful distributed computing frameworks available today. Its combination of fast, in-memory computing with an architecture that’s easy to understand has made it popular for users working with huge amounts of data.
While Spark shines at operating on large datasets, it still requires a solution for data persistence. HDFS is a common choice, but while it integrates well with Spark, its disk-based nature can impact performance in real-time applications (e.g. applications built with the Spark Streaming libraries). Also, Spark does not have a native capability to commit transactions.
Making Spark Even Better
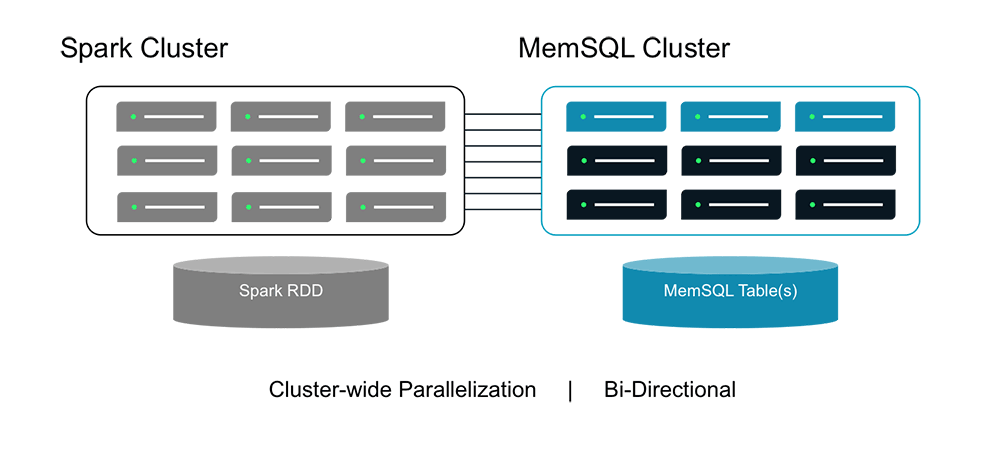
That’s why SingleStore is releasing the SingleStore Spark connector, which gives users the ability to read and write data between SingleStore and Spark. SingleStore is a natural fit for Spark because it can easily handle the high rate of inserts and reads that Spark often requires, while also having enough space for all of the data that Spark can create.
Operationalize and streamline Spark deployments with the SingleStore Spark Connector – Click to Tweet
The SingleStore Spark Connector provides everything you need to start using Spark and SingleStore together. It comes with a number of optimizations, such as reading data out of SingleStore in parallel and making sure that Spark colocates the data in its cluster with SingleStore nodes when SingleStore and Spark are running on the same physical machines. It also provides two main components: a SingleStoreRDD class for loading data from a SingleStore query and a saveToSingleStore function for persisting results to a SingleStore table.
We’ve made our connector open source; you can find the project here. Check it out and let us know how it works.
Get The SingleStore Spark Connector Guide
The 79 page guide covers how to design, build, and deploy Spark applications using the SingleStore Spark Connector. Inside, you will find code samples to help you get started and performance recommendations for your production-ready Apache Spark and SingleStore implementations.
Download Here