
The Current Organizational Data Dilemma
Today, many companies have years of investment in traditional databases from Oracle, SAP, IBM, Microsoft and others. Frequently these databases and data warehouses have long outlived their ability to cost-effectively perform and scale. These solutions also offer mixed options when it comes to cloud deployments.
Over the past decade, data-driven organizations looked to new methods such as Hadoop and NoSQL to solve data challenges. Hadoop has proven to be a good place to store data, but a challenging place for production data workflows. Gartner noted at a recent conference that only 17 percent of Hadoop deployments are in production in 2017. Also adding a ‘SQL layer” on top of the Hadoop Distributed File System is not a path for building a robust, transaction-capable datastore.
Similarly, NoSQL is a great place to store simple key-value pairs, but a challenging place for analytics. A prominent Gartner analyst notes, “The term NoSQL, in my opinion is meaningless and useless… As the term NoSQL refers to a language, the better term for these DBMSs would be non-relational.” Non-relational, of course, can make sophisticated analytics tricky.
Given these lackluster alternatives, organizations need a modern, scalable solution for database and data warehouse workloads that frees them to deploy flexible data architectures of their choosing. Such a solution would also include seamless paths to the cloud across all workloads.\Dilemma Snapshot
- Organizations are awash in on-premises database and data warehouse deployments from traditional vendors
- These solutions are often coupled with technology lock-in, especially in the form of hardware appliances and the restriction to run in specified environments; cloud options are limited
- Many traditional solutions have massive complexity, including hundreds of thousands of lines of custom code due to shortcomings of legacy technology
- Shortcomings resulted in bolt-on solutions to address scale, speed, and concurrency issues
Data Architecture Challenges Ahead
Handling data securely, cost-effectively and at scale requires effort across multiple areas.\Cost Reduction\Organizations continually seek to reduce license, maintenance and operational costs of data solutions. Legacy offerings that require specific hardware appliances no longer meet the needs of modern workloads.\Contract and Licensing Complexity\Complex contract and licensing models for traditional solutions make them impractical for organizations aiming to move quickly, adapt to changing conditions, and drive results with new data streams.\Performance at Scale\Hardware-centric appliances or single-server solutions that do not automatically distribute the workload are not capable of delivering performance at scale.\Security Requirements\With data at the core of every organization, security remains critical and databases and data warehouses must provide a comprehensive and consistent security model across deployments from on-premises to the cloud.\Cloud Choices\As the world goes cloud, organizations need the ability to quickly and safely move data workflows and applications to a cloud of their choice. These migrations should happen seamlessly and without limitations. An option to choose clouds (public, private, hybrid, and multi-cloud) should be on the table at all times.
Customer Use Cases
Here’s how organizations have moved from Oracle while retaining options for on-premises and the cloud.
Moving from Oracle to SingleStore instead of a Data Lake
In this first use case we explore a large financial institution moving to SingleStore after trying unsuccessfully to move data applications from traditional datastores to Hadoop.\Need\The overarching need was driven by a desire to move off of legacy systems, such as Oracle, Netezza, SybaseIQ, and Teradata. These systems were not achieving the required levels of performance, and were becoming painfully expensive for the organization to support.\Exploration\The data team at the bank initially attempted to migrate to a Hadoop-based data lake. Unfortunately, data application migration was taking approximately one year per application. Much of the delay was due to requirements to retrain relational database management system (RDBMS) developers on new languages and approaches such as MapReduce, and using SQL layers that “kind of” provide SQL functionality, but frequently fall short in terms of SQL surface area and robustness.\Solution\Adding SingleStore as a data application destination, with complete coverage for INSERT, UPDATE, and DELETE commands, reduced application migration time down to one month. This new solution using SingleStore now supports one of the largest data warehouses in the bank. Additionally, the workflows that were migrated to SingleStore are completely cloud-capable.
Moving from Oracle to SingleStore Instead of Exadata
A large technology company faced a performance need for its billing system. It had plenty of Oracle experience in-house, but the Oracle solutions proposed were priced prohibitively and could not deliver the necessary performance.\Need\As part of an expansion plan for its billing system, the large technology company sought an effective and affordable solution to expand from 70,000 to 700,000 transactions per second.\Exploration\The team briefly considered a solution with Oracle Exadata which topped out at 70,000 transactions per second. Part of this is due to the fact that Oracle ingests data using the traditional I/O path, which cannot keep up with the world’s fastest workloads.
SingleStore on the other hand, using a distributed, memory-optimized architecture, achieved six million UPSERTs per second in initial trials. After server and network optimizations, that same solution is nearing 10 million UPSERTs per second.\Solution\Implementing SingleStore helped save millions in avoiding the high cost of Oracle solutions.\UPSERTs provide computational efficiency compared to traditional INSERTs. For example, with UPSERTs, data is automatically pre-aggregated allowing for faster queries. Additionally, SingleStore configurations perform on low-cost-industry-standard servers, providing dramatic savings on hardware, and an easy path to move to the cloud.
Moving from Oracle to SingleStore and Introducing Tableau
A global fixed-income investment firm with nearly \$500 billion in assets under management set a strategy to regain control of database performance and reduce its reliance on Oracle.\Need\The firm faced a dilemma with its existing Oracle configurations in that direct, end user queries negatively impacted performance. At times, queries from individual users impacted the database for the company as a whole. Concurrent with this performance challenge was an organizational desire to “not bet the farm on Oracle.”\Exploration\The team looked for a solution that would provide the scale and performance needed from a database perspective but also the ability to implement ‘query’ governance using a business intelligence tool.\Solution\Ultimately the team chose SingleStore due to its RDBMS foundation, and the ability to scale using a distributed, memory-optimized architecture. For business intelligence, the firm selected Tableau, and Tableau includes a native SingleStore connector. The organization now has a cloud-capable architecture that allows it to move to any public cloud of its choice at any time.
Creating a Migration Plan
Migrating from traditional databases and data warehouses takes planning, but more importantly it takes organizational effort and a will to move to new solutions. Here are several tips that can streamline your journey.
Assessment
You can begin by taking an inventory of database and data warehouse infrastructure, including systems from Oracle, SAP, Microsoft and IBM, as well as Netezza, Vertica, Greenplum and others. These products span the database to data warehouse spectrum.
For products with a long history, aim to determine the degree of stickiness due to custom code. For example, Oracle stored procedures are widely used in many organizations and reliance on this custom code factors heavily in the ease of migration.
Put yourself in a position to succeed by identifying older data applications that have struggled with performance or become painfully expensive.
Planning
Next, identify easy applications for migration. For example, consider the following popular use cases for quick wins, high success potential, low risk, rapid cost reduction, and immediate impact.\Exadata Replacements\Exadata replacements are appropriate in cases where customers have been required to buy Exadata for performance, but may not need the entire feature set. Similar reasoning can be applied to SAP HANA and IBM Db2.\Large-scale Databases\Often for real-time data warehousing solutions, customers prefer to consolidate many databases into a single deployment. This can be accomplished with a distributed system that scales well across dozens or hundreds of nodes.\High-speed Ingest\For newer workloads, especially those around internet-scale tracking, IoT sensors, or geospatial data collection, capturing all of the data is critical to the solution. Legacy datastores tend to struggle with these configurations whereas newer distributed architectures handle high speed ingest easily.\Low-latency Queries\Query performance is a perennial database and data warehouse requirement. However, many legacy solutions are not equipped to handle the real-time needs of modern workloads, in particular the ability to handle sophisticated queries on large datasets, especially when that dataset is constantly changing. Systems that can handle low latency queries on rapidly updating data serve modern workloads effectively.\High Concurrency\When data applications reach a level of adoption they face a blessing and a curse. On the one hand, continued adoption validates the application success. On the other hand, too many concurrent users can negatively impact performance. Data applications that demand a high level of user concurrency are solid candidates to move to a more powerful, memory-optimized distributed system.
Using SingleStore and Oracle Together
SingleStore fits data ecosystems well, as exemplified by several features. First, SingleStore offers users flexible deployments – whether it’s hybrid cloud, on-premises, VMs, or containers. Second, there are tools such as the SingleStore Spark Connector for high-speed, highly-parallel connectivity to Spark, and SingleStore Pipelines which lets you build real-time pipelines and import from popular datastores, such as HDFS, S3, and MySQL. And SingleStore is a memory-first engine, designed for concurrent data ingest and analytics. These ingredients make SingleStore a perfect real-time addition to any stack.
Many customers combine SingleStore with traditional systems, in particular Oracle databases. SingleStore and Oracle can be deployed side-by-side to enhance scalability, distributed processing, and real-time analytics.\SingleStore for Real-Time Analytics\Data can be copied from Oracle to SingleStore using a data capture tool, and analytical queries can be performed in real time.\

SingleStore for Stream Processing with Kafka or Spark\SingleStore can serve as the stream processing layer in front of an Oracle database. Use Apache Kafka or Apache Spark to help build real-time data pipelines.\
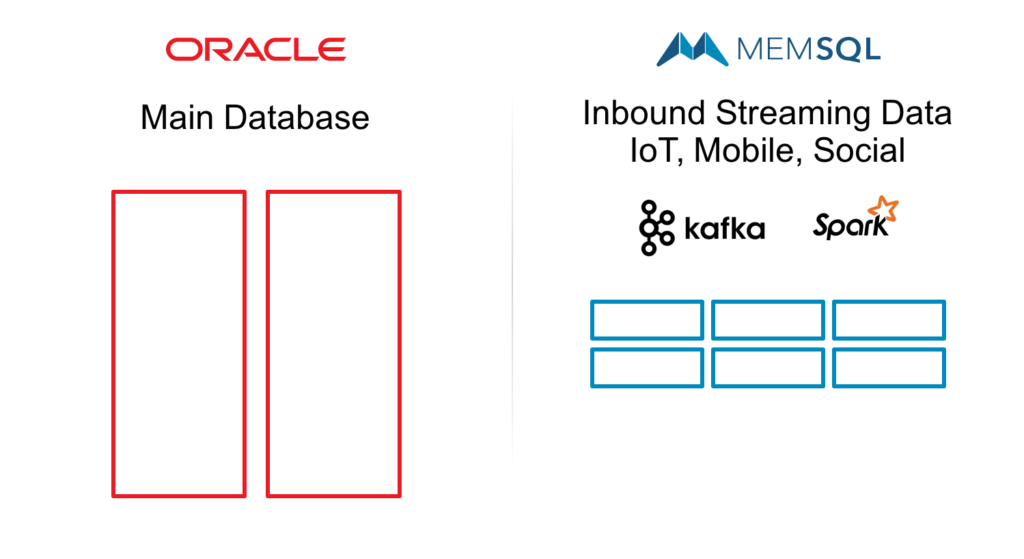
SingleStore as the High-Speed Ingest Layer\Using SingleStore as the data ingest layer on top of an Oracle database allows ingest at in-memory speed.\

Key Considerations in Migrating from Oracle
In particular when migrating from Oracle, the following situations require more time, planning and potential development work. It can be complex, but ultimately provide high reward. Be sure to dedicate enough of a planning cycle and focus on parallel deployments to ensure success.
- Databases with heavy reliance on stored procedures. While they can be migrated, the custom code requires time and energy to move.
- Databases embedded deep within Oracle ERP systems (e.g. Peoplesoft) can require more effort as they can be part of a locked-down, proprietary solution.
- Databases connected to current critical path infrastructure should be migrated after a successful approach focused on adding analytics to an existing application.
- Databases connected to applications with significant trigger logic. This may require logic to be re-written outside of SingleStore.
The newest version of SingleStore includes extensibility across stored procedures, user-defined functions, and user-defined aggregates. In some cases, customers will be able to rework certain procedures into the SingleStore extensibility language MP/SQL for massively parallel SQL.
Development, Testing, and Deployment
Once a migration candidate has been identified, testing and development can begin. With a cloud-native database such as SingleStore, customers can develop and test on any public cloud including AWS, AWS GovCloud, Azure or Google. Or they can run development and testing within their own infrastructure.
SingleStore provides complete flexibility to choose industry-standard hardware configurations that run anywhere. The minimum requirements for a SingleStore node are Linux, 4 cores, and 8GB of RAM. The rest is up to customer choice.
A typical test and deployment process might take the following approach.
- Identify the data application for migration. Export the data set. Import the data to a new solution such as SingleStore and run sample queries
- Scale the solution using options in the cloud or on-premises
- Run additional queries for full coverage
- Connect the appropriate applications or business intelligence tools
- Refine and test the solution across all operational requirements
- Move from development and testing to pre-production
- Move to production deployments
Understandably there may be many more steps to migrate specific applications. Making progress begins with the first successful migration.
Further Reading
The Real-Time Data Warehouse for Hybrid Cloud
For more information please visit www.singlestore.com






