Keeping it Straight
Data value comes from sharing, so staying organized and providing common data access methods across different groups can bring big payoffs.
Companies struggle daily to keep data formats consistent across applications, departments, people, divisions, and new software systems installed every year.
Passing data between systems and applications is called ETL, which stands for Extract, Transform, and Load. It is the process everyone loves to hate. There is no glamour in reconfiguring data such as date formats from one system to another, but there is glory in minimizing the amount of ETL needed to build new applications.
To minimize ETL friction, data architects often design schemas in third normal form, a database term that indicates data is well organized and unlikely to be corrupted due to user misunderstanding or system error.
Getting to Third Normal Form
The goal of getting to third normal form is to eliminate update, insertion, and deletion anomalies.
Take this employee, city, and department table as an example:
| employee_id | employee_name | employee_city | employee_dept |
|---|---|---|---|
| 101 | Sam | New York | 22 |
| 101 | Sam | New York | 34 |
| 102 | Lori | Los Angeles | 42 |
Update Anomalies
If Sam moves to Boston, but stays in two departments, we need to update both records. That process could fail, leading to inconsistent data.
Insertion Anomalies
If we have a new employee not yet assigned to a department and the ‘employee_dept’ field does not accept blank entries, we would be unable to enter them in the system.
Deletion Anomalies
If the company closed department 42, deleting rows with department 42 might inadvertently delete employee’s information like Lori’s.
First Normal Form to Start
First normal form specifies that table values should not be divisible into smaller parts and that each cell in a table should contain a single value.
So if we had a customer table with a requirement to store multiple phone numbers, the simplest method would be like this
| customer_id | customer_name | customer_phone |
|---|---|---|
| 101 | Brett | 555-459-8912 555-273-2304 |
| 102 | Amanda | 222-874-3567 |
However, this does not meet first normal form requirements with multiple values in a single cell, so to conform we could adjust it to
| customer_id | customer_name | customer_phone |
|---|---|---|
| 101 | Brett | 555-459-8912 |
| 101 | Brett | 555-273-2304 |
| 102 | Amanda | 222-874-3567 |
Second Normal Form
2nd normal form requires that
- Data be in 1st normal form
- Each non-key column is dependent on the tables complete primary key
Consider the following example with the table STOCK and columns supplier_id, city, part_number, and quantity where the city is the supplier’s location.
| supplier_id | city | part_number | quantity |
|---|---|---|---|
| A22 | New York | 7647 | 5 |
| B34 | Boston | 9263 | 10 |
The primary key is (supplier_id, part_number), which uniquely identifies a part in a single supplier’s stock. However, city only depends on the supplier_id.
In this example, the table is not in 2nd normal form because city is dependent only on the supplier_id and not the full primary key (supplier_id, part_number).
This causes the following anomalies:
Update Anomalies
If a supplier moves locations, every single stock entry must be updated with the new city.
Insertion Anomalies
The city has to be known at insert time in order to stock a part at a supplier. Really what matters here is the supplier_id and not the city. Also unless the city is stored elsewhere a supplier cannot have a city without having parts, which does not reflect the real world.
Deletion Anomalies
If the supplier is totally out of stock, and a row disappears, the information about the city in which the supplier resides is lost. Or it may be stored in another table, and city does not need to be in this table anyway.
Separating this into two tables achieves 2nd normal form.
| supplier_id | part_number | quantity |
|---|---|---|
| A22 | 7647 | 5 |
| B34 | 9263 | 10 |
| supplier_id | city |
|---|---|
| A22 | New York |
| B34 | Boston |
Third Normal Form
We’re almost there! With 1st normal form, we ensured that every column attribute only holds one value.
With 2nd normal form we ensured that every column is dependent on the primary key, or more specifically that the table serves a single purpose.
With 3rd normal form, we want to ensure that non-key attributes are dependent on nothing but the primary key. The more technical explanation involves “transitive dependencies” but for the purpose of this simplified explanation we’ll save that for another day.
In the case of the following table, zip is an attribute generally associated with only one city and state. So it is possible with a data model below that zip could be updated without properly updating the city or state.
| employee_id | employee_name | city | state | zip |
|---|---|---|---|---|
| 101 | Brett | Los Angeles | CA | 90028 |
| 102 | Amanda | San Diego | CA | 92101 |
| 103 | Sam | Santa Barbara | CA | 93101 |
| 104 | Alice | Los Angeles | CA | 90012 |
| 105 | Lucy | Las Vegas | NV | 89109 |
Splitting this into two tables, so there is no implied dependency between city and zip, solves the requirements for 3rd normal form.
| customer_id | customer_name | zip |
|---|---|---|
| 101 | Brett | 90028 |
| 102 | Amanda | 92101 |
| 103 | Sam | 93101 |
| 104 | Alice | 90012 |
| 105 | Lucy | 89109 |
| zip | city | state |
|---|---|---|
| 90028 | Los Angeles | CA |
| 92101 | San Diego | CA |
| 93101 | Santa Barbara | CA |
| 90012 | Los Angeles | CA |
| 89109 | Las Vegas | NV |
Benefits of Normalization
Normalizing data helps minimize redundancy and maintain the highest levels of integrity. By organizing column attributes and the relations between tables, data administrators can design systems for efficiency and safety.
More specifically, normalization helps ensure
- Data is not unnecessarily repeated within a database
- Inserts, modifications, and deletions only have to happen once in a database
Data Management with Star Schema
Star schema is an approach of arranging a database into fact tables and dimension tables. Typically a fact table records a series of business events such as purchase transactions. Dimension tables generally store fewer records than fact tables but may have more specific details about a particular record. A product attributes table is one example.
Star schemas are often implemented in a denormalized fashion, with typical normalization rules relaxed. The advantage of this can be simpler reporting logic and faster performance as data may be stored multiple ways to facilitate queries.
The disadvantage of this approach is that integrity is not necessarily enforced through the model leaving room for an update in one place that may not successfully propagate elsewhere.
Further, with normalization, a large variety of data analytics tools and approaches can be used to query data without explicit advanced knowledge. Without normalization, schemas tend to become isolated to specific functions and less flexible across a large organization.
Flexible Star Schema Deployments with SingleStore
Is it possible or desirable to merge normalization and star schemas? Sure.
While data management strategies can be very application specific, retaining data in the most universally accessible forms benefits larger organizations. With normalization, data organization transcends application use cases and database systems.
Star schemas often skip normalization for two reasons: simplicity of queries and performance.
Regarding query simplicity, this is a tradeoff between application-specific approaches and data ubiquity across an organization. Independent of the database, this tradeoff remains.
When it comes to performance, historical systems have had challenges with operations like fast aggregations, and a large number of joins driven by third normal form. Modern database architectures have eliminated those performance challenges.
With a solution like SingleStore, a memory-optimized, relational, distributed database, it is possible to achieve normalization and performance. Even with the increased number of tables, and subsequent joins, often resulting from third normal form, SingleStore maintains stellar performance. And the core relational SQL model makes it easy to create or import a range of tables as well as maintain relations between tables.
In the next sections, we’ll explore table types in SingleStore and the associated benefits.
Using Multiple Table Types in SingleStore
SingleStore includes two table types:
- A rowstore table where all the data is retained in memory and all data is persisted to disk
- A columnstore table where some data resides in memory and all data is persisted to disk
Using these two table types is it possible to design a wide range of schema configurations.
Contrary to popular belief, determining whether you use an all-memory or memory-plus-disk table has less to do with data size, and more with how you plan to interact with the data.
Columnstores are useful when rows are added or removed in batches, and when queries touch all or many records but only for a few columns. Aggregations like Sum, Average, and Count are good examples.Rowstores work well when operating over whole rows at a time. This includes updates to individual attributes or point lookups.For more detail on rowstores and columnstores check out
Should You Use a Rowstore or a Columnstore? From SingleStore VP of Engineering Ankur Goyal
Creating a Star Schema in SingleStore
Whether or not you lean towards normalization, SingleStore makes it easy to create a star schema within a single database across multiple table types.
Figure: Basics of a star schema with Fact and Dimension tables
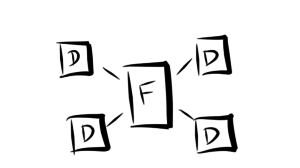
Both dimension tables and fact tables can be row or column based depending on requirements, which should be focused more on data use and operations rather than just capacity.
| Dimension Tables | Fact Tables | Recommendations |
|---|---|---|
| Row | Row | Most flexible option for performance across a wide range of queries. Best overall performance for small scans (1000s of rows). |
| Row | Column | Best when there is lots of Fact data. Performance will be especially good when queries involve lots of scans. |
| Column | Column | Good when there is lots of Dimension data and the data is append-only. |
Opportunities for Normalization and Star Schema
Whether your preferences sway towards normalization, star schema, or a combination, SingleStore provides a simple and easy way to achieve a standard data model that leverages the relational capabilities of ANSI SQL.
Beyond that, the SingleStore architecture delivers the utmost in performance and scalability, including the ability to ingest data from multiple systems and datastores for real-time analytics. This is a frequent use case for large corporations that need to track a variety of data sources with consolidated reporting.
Of course handling all of this in real time brings another level of visibility and usefulness to the data. Now businesses can get a pulse of activity in the moment, allowing them to adapt and learn in real time.
Interested in giving SingleStore a try? Download here http://www.singlestore.com/cloud-trial/
References
https://www.wikipedia.org/
http://beginnersbook.com/2015/05/normalization-in-dbms/
https://www.1keydata.com/database-normalization/second-normal-form-2nf.php
http://www.essentialsql.com/get-ready-to-learn-sql-11-database-third-normal-form-explained-in-simple-english/