
The database market is large and filled with many solutions. In this post, we will take a look at what is happening within AWS, the overall data landscape, and how customers can benefit from using SingleStore within the AWS ecosystem.
Understanding the AWS Juggernaut
At AWS re:Invent in December 2017, AWS CEO Andy Jassy revealed that the business is at a revenue run rate of \$18 billion, growing 42 percent per year. Those numbers are staggering and showcase the importance Amazon Web Services now plays in the technology plans of nearly every major corporation.
Along with eye popping revenue numbers, AWS has continued to offer an unprecedented number of new features every year. At the conference, AWS claimed it has shipped 3,951 new features and services in the five years since the first keynote address by CTO Werner Vogels.

This kind of feature and services proliferation can be daunting. Let’s explore a way to simplify.
Navigating the Data Landscape
The data landscape is broad, but can be simplified into a few key areas. In particular, we can assess solutions based on their ability to work with relational data, and their ability to support analytical or operational workloads. This breaks the market into four distinct categories: Databases, Data Warehouses, NoSQL, and Data Lakes.
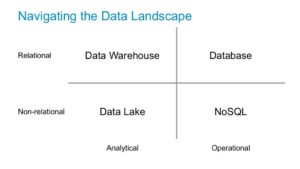
Let’s take a closer look at each of these categories and the AWS solutions within each.
Databases
AWS offers a number of database choices, and one of the popular services is Aurora, which takes single server database systems such as PostgreSQL and MySQL and implements them as a service. While these solutions offer some scalability benefits from the bare database instances, at the core, PostgreSQL and MySQL are single server systems.
This works extremely well if your dataset fits into a single server, and if so, you should celebrate and enjoy the benefits of being able to deploy such an architecture.
Data Warehouses
Redshift is the most popular data warehouse on AWS and works well for offline analytics. In general, data processing systems can be ranked on their ability to load data quickly, deliver rapid responses to queries, and support for simultaneous users. Redshift does well on query performance, but can hit stumbling blocks for fast ingest and support for a large numbers of concurrent users. For example, the Redshift documentation advises
As a best practice, we recommend using a total query slot count of 15 or lower.
AWS also offers solutions for Hadoop (Elastic MapReduce) and ad hoc querying of data on object stores (Athena), but these tend to be focused on offline analytics without a need for a stringent, subsecond service level agreement.
Data Lakes
While Hadoop became synonymous with the Data Lake term, today more people are focusing on object stores such as S3 as a static repository for all of their data. S3 in many respects is the new Data Lake and serves this market extremely well.
NoSQL
The NoSQL movement was born due to legacy single server database challenges achieving scale and performance. But in achieving the performance and scale, NoSQL datastores left one thing behind…SQL! This is in part why single server databases such as MySQL and PostgreSQL continue to thrive in AWS…they support the functionality customers want.
Amazon offerings in the NoSQL arena include DynamoDB and EMR.
Another reason cited for the rise of NoSQL is the flexibility to work with different data types such as JSON, and the ability to change the database schema over time.
Today, many new distributed solutions offer native SQL engines, flexible data models, and the ability to alter the schema while online. This begs the question of where NoSQL datastores fit going forward.
Adapting to the New Data Landscape
Rapid changes taking place in the data industry require a new look at the overall sector and how developers and architects should approach new application deployments.
Deflated Expectations of Hadoop
First is the recognition that data lakes will not solve the operational workloads that it was initially thought they would. The lack of transactional functionality such as INSERT, UPDATE, and DELETE for file systems and object stores relegated them to wonderful places to store data, but terrible places to process data. Database and data warehouse functionality is still sorely needed.
NoSQL Fades to a Feature
With NoSQL, the lack of analytics functionality means these datastores only form part of a solution, but not enough to provide the analytic context for modern applications. Today many people use Spark as part tow truck and part ambulance to rescue data out of NoSQL datastores where analytics are all but impossible. With new solutions offering distributed scale, persistence, and performance while retaining SQL, it begs the question how long NoSQL will survive on its own.
Transactions and Analytics Together
For modern applications, new datastores offer the ability to combine both transactional and analytical operations in one system. This provides a fast path to creating real-time applications. When data can land and be processed within the same system there is no need for an ETL (Extract, Transform, and Load) process.
Today, all of the major analyst firms promote this vision in one way or another. Gartner uses the term HTAP, or Hybrid Transaction/Analytical Processing.
Enabled by in-memory computing technologies, HTAP architectures support the needs of many new application use cases in the digital business era, which require scalability and real-time performance. Data and analytics leaders facing such demands should consider the following HTAP solutions supported by in-memory computing.
451 Research takes a slightly different approach by identifying this market as HOAP, or Hybrid Operational Analytical Processing.
…we expect HOAP workloads to rapidly account for a significant proportion of incremental database revenue, and that supporting them will come to be expected in any mainstream operational database product or service.
Finally, Forrester has also identified this new united transactional and analytical workload category, which they refer to as Translytical.
Analytics at the speed of transactions has become an important agenda item for organizations. Translytical data platforms, an emerging technology, deliver faster access to business data to support various workloads and use cases. Enterprise architecture pros can use them to drive new business initiatives.
Taking the preceding into account, we can envision a highly simplified data landscape:

In this configuration, SingleStore serves as both a database and data warehouse serving operational and analytical needs. AWS S3 serves as a data lake to retain long term static data.
Recapping AWS and SingleStore Data Solutions
Let’s take a look again at each of the original data sectors and when to use or not use AWS solutions compared to SingleStore.
Databases from AWS and SingleStore
Aurora tends to dominate AWS and should be used when
- The dataset easily fits into a single server
- The performance requirements can be addressed by a single server
- Workloads are write-centric without a need for simultaneous reads and writes
SingleStore should be used when
- The dataset size exceeds the capacity of a single server
- The performance requirements outpace those provided by a single server
- There is a need for simultaneous read and write workloads
For more information on this topic check out a recent article in Data Center Knowledge, Graduating from Single Server Databases.
Data Warehouses from AWS and SingleStore
Redshift is the popular data warehouse on AWS and should be used when
- There are no requirements for fast data ingest or high user concurrency
SingleStore is a single product that provides both database and data warehouse functionality. It should be used when
- There is a requirement for fast ingest; or
- There is a requirement for a large amount of user concurrency
Data Lakes on AWS
While Hadoop implementations are declining, object stores such as S3 provide a valuable service for static data and are quickly becoming the new “data lake”.
SingleStore includes native ingest capabilities from S3, such as the ability to build real-time data pipelines streaming data from S3 into SingleStore.
CREATE PIPELINE myS3pipeline AS
LOAD DATA S3 "mys3bucket/mydata/"
CREDENTIALS '{"aws_secret_access_key": "my_aws_secret_access_key", "aws_access_key_id": "my_aws_access_key_id"} '
INTO TABLE mytable;
NoSQL on AWS
While DynamoDB provides a useful tool for key-value or document data storage, it does not provide inherent analytical capabilities, and therefore requires additional systems for a complete solution. This is also the case with datastores, such as Cassandra or MongoDB. Given that new distributed datastores such as SingleStore offer scale, performance, and SQL, it begs the question for where NoSQL solutions fit.
For more on this topic please see the Network World article, The Hidden Costs of NoSQL.
SingleStore and AWS
Together, SingleStore and AWS provide a compelling platform for building real-time applications. SingleStore can handle both database and data warehouse workloads, which fit with the direction of new applications to combine transactional and analytical requirements. AWS provides useful services such as S3, as well as the most comprehensive Infrastructure-as-a-Service to stand up powerful solutions.
Many SingleStore customers such as Tapjoy and Appsflyer deploy SingleStore on AWS today. Other customers such as Myntra have also found ways to integrate SingleStore with their existing AWS solutions such as Redshift to build a pipeline they refer to as Meterial.
For more information on using SingleStore and AWS please connect with us at info@singlestore.com or visit www.singlestore.com.






