
Bill Vorhies of Data Science Central and Rick Negrin of SingleStore recently delivered a webinar on data lakes and the use of Hadoop in the age of operational machine learning (ML) and artificial intelligence (AI). In this blog post, we summarize some of the key points from the webinar, as a preview for the webinar. You can also view the recorded webinar at any point.
Businesses need flexible access to their data to make the best decisions. Unfortunately, the systems in use today impose complexity and structural delays. SingleStore, a fast, fully scalable relational database that supports ANSI SQL, can simplify your data processing architecture and speed decision-making. SingleStore can also make current, accurate data available for use by ML and AI.
The Promise – and Peril – of Data Lakes
Businesses know that they need to understand their customers better and make fast, accurate decisions to deliver superior customer experiences. Data lakes are meant to be the answer to this need.
The promise of data lakes was to take in masses of data quickly and make it available for exploration and decision-making. This prospect has led to very rapid growth in Hadoop, the technology underlying most data lake implementations.
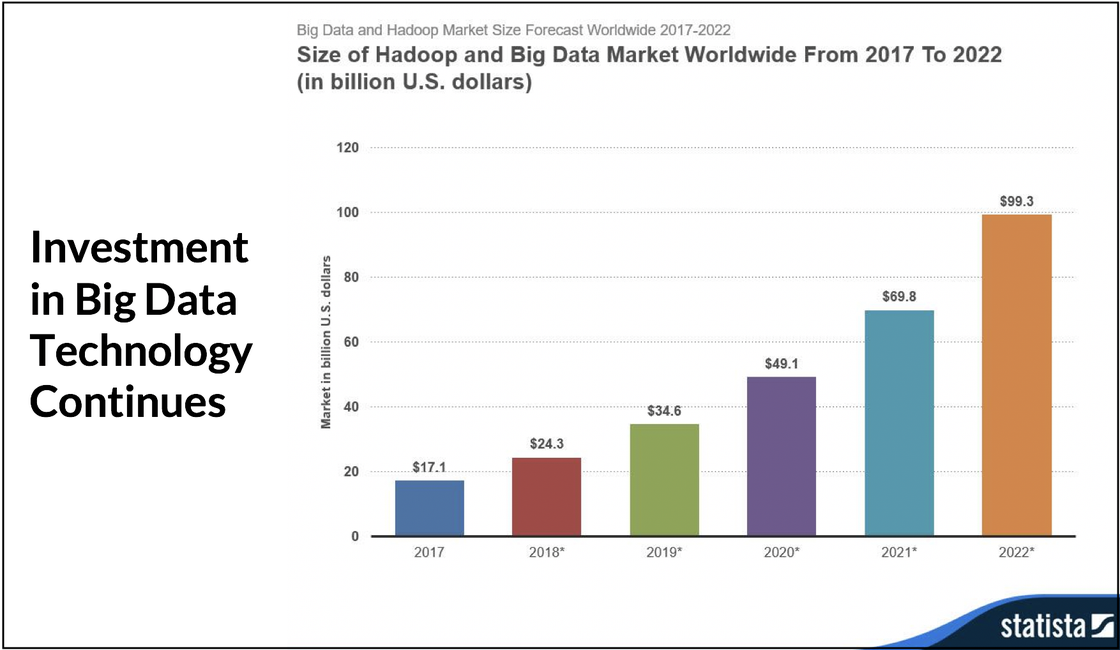
Unfortunately, only the first part of this promise – taking in masses of data quickly – has been kept. Hadoop is fully scalable, so it can use large numbers of servers based on industry-standard hardware to handle large ingest volumes.
However, the databases used with Hadoop are NoSQL databases, not relational databases that support SQL. We here at SingleStore have an excellent blog post on why NoSQL is no longer needed for most use cases. Briefly, NoSQL databases were created largely to offer the scalability that was previously lacking in relational databases that support SQL. However, they offered scalability at the cost of removing most relational functionality, transaction capability, and SQL support.
This forced architects and developers to choose between non-scalable traditional databases on the one hand and scalable NoSQL databases on the other. Now that NewSQL databases in general, and SingleStore in particular, offer fully scalable relational databases that support SQL, most of the use cases for NoSQL disappear. (Many of the remaining use cases fall into two groups: rapid ingest of data and long-term storage of data as an archive, both at low cost.)
The lack of relational functionality, transactions, and SQL support means that data ingested into Hadoop is not readily available for use in meeting the second part of the promise – making the data available for exploration and decision-making. It may also not be available for many of the features you might want to add to an application, as explained in this post about a failed implementation of MongoDB.
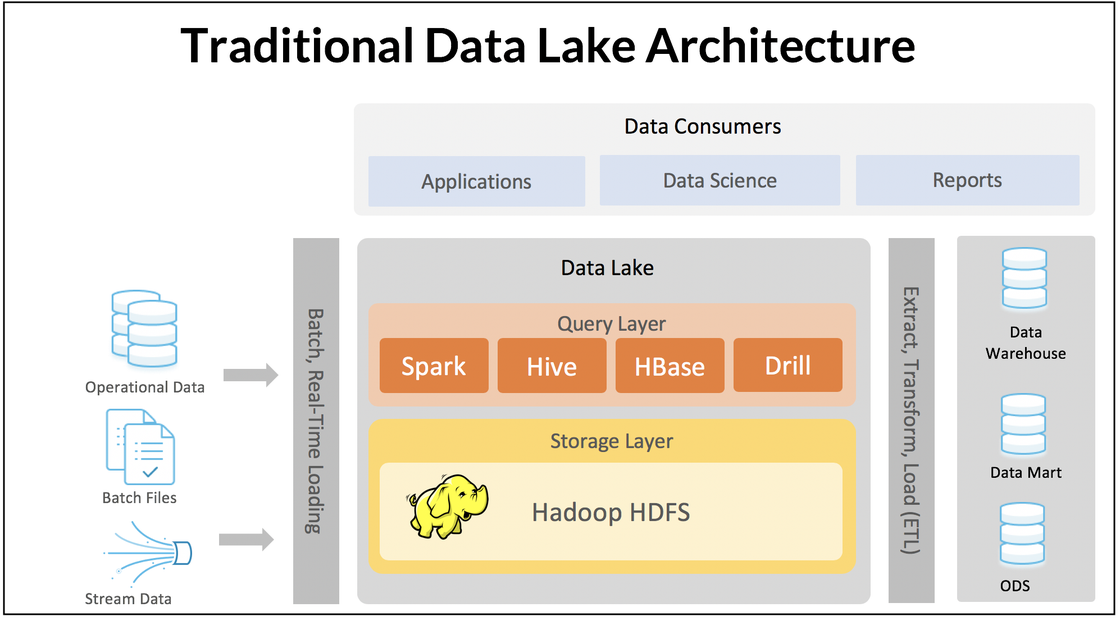
To address this problem, additional data processing steps, tools, and new databases were developed. A query layer composed of tools such as Apache Spark and Hive promises access to Hadoop data. An extract, transform, and load (ETL) process takes data stored in Hadoop’s NoSQL database, HDFS, and stores it in data warehouses, data marts, and operational data stores (ODSes). The use of all of these additional layers and processes creates a complex infrastructure that is slow, complicated, hard to maintain and use.
How SingleStore Makes a Difference
SingleStore is a fast, scalable, fully relational database that supports ANSI standard SQL. SingleStore offers the best of both worlds: it’s fully scalable on industry-standard servers such as Hadoop, and it is fully relational, offering a consistent database with transaction support and a standard SQL interface.
SingleStore is described as “translytical”; a SingleStore database can process transactions and queries for data analytics simultaneously. There is no ETL step, and no need for specialized tools for making unstructured data into (more or less) structured data. Your data is never not in a relational database; it’s always stored in records, always consistent, and always accessible via familiar SQL queries and all the SQL-compatible tools out there.
The advantages of this for machine learning and AI are clear. You can run machine learning against all your data, old and new, in one process. AI programs are always operating on all the data your organization has. AI programs have instant access to the newest information as it comes in. The advantages of a full implementation of SingleStore are clear, both for operational simplicity and for ML/AI readiness.
SingleStore-Based Data Lake Alternatives
If you have a traditional data lake architecture, you can use SingleStore in two different ways:
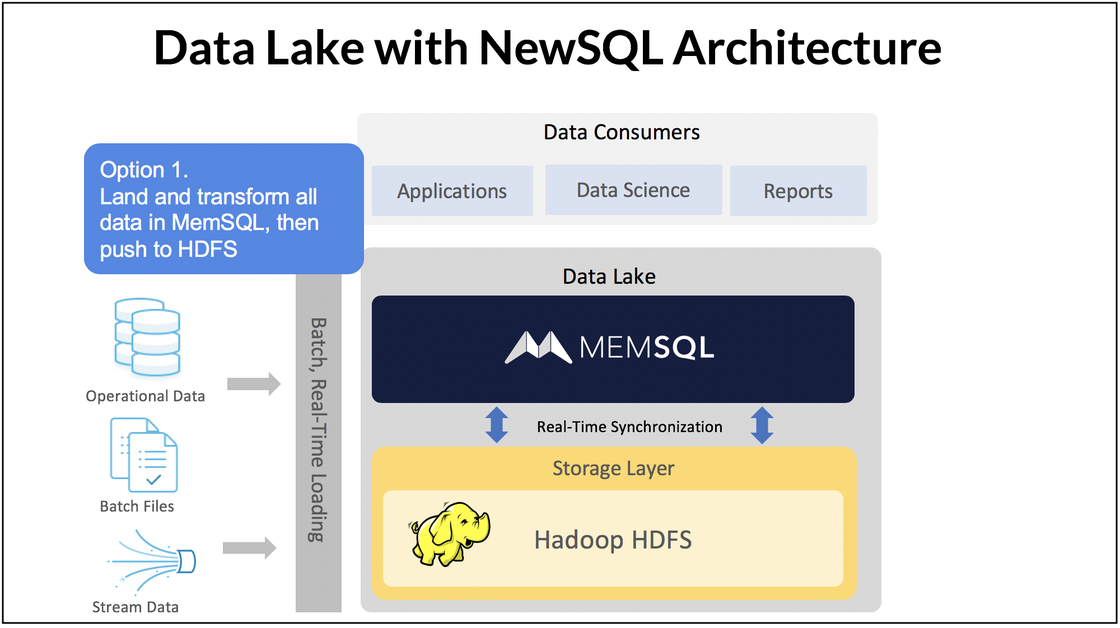
- SingleStore with Hadoop. SingleStore can replace the tools in the query layer of a traditional data lake and eliminate the need for a separate ETL process and separate data warehouses, data marts, and operational data stores, creating a much simpler and faster system. SingleStore may be used in a smaller role, for ingest or as a query accelerator, with Hadoop retained as a long-term data store.
- SingleStore Replaces Hadoop. You can simply load data directly into SingleStore and query data directly from SingleStore. Hadoop is designed out. (This is what you would have done if SingleStore had been available when you first invested in Hadoop, query tools, ETL processes, and data warehouses, data marts, and operational data stores.)
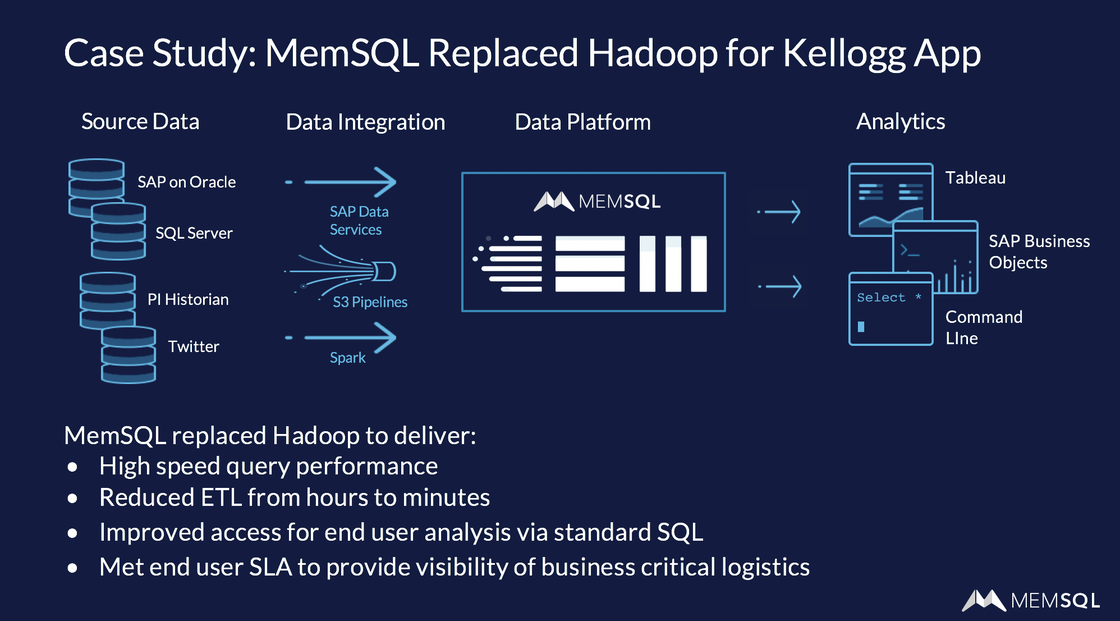
The webinar includes a case study of how Kellogg, the food company, replaced Hadoop and Hive with SingleStore. It got much faster query performance, ETL-like processing in minutes instead of hours, and the ability to use SQL again. All in all, a huge win.
Q&A
Attendee questions, and Rick’s answers, included:
- Does SingleStore support semi-structured data such as text, JSON, Avro, and Parquet-formatted files? Yes. You can pull in CSV files, JSON, and Avro natively now; a future release will include native Parquet support.
- For queries, can I use Java or Python Spark ML or sklearn functions? Any technology that has a MySQL connector can connect directly with SingleStore and run queries. This works with Spark or just about any language, as most languages have a MySQL connector or an ODBC or JDBC driver. In addition, SingleStore has developed native connectors for key technologies such as Spark and Python, optimized for use with SingleStore and supporting all of its functionality.
- Can SingleStore integrate with pretrained models in TensorFlow? Yes, and we’ve demonstrated this. You can use TensorFlow libraries to evaluate the data and create a model and then use SingleStore pipelines to ingest data against it. We have a video (about 12 minutes long) showing the TensorFlow/SingleStore combination in action.
- What is the largest datastore that SingleStore currently supports? There’s really no known limit as to how much data SingleStore supports. We have customers that have hundreds of terabytes stored in SingleStore. We have one customer who has hundreds, and soon will have thousands of databases stored in a single cluster of SingleStore. We have some that are doing 10-15 million inserts per second by using a very large cluster and mostly using the rowstore – we scale in lots of ways.
- Do you integrate with SAS? Yes, we have a formal certification from SAS that SingleStore and SAS work together. It’s easy; you just use the existing MySQL connector.
Watch the SingleStore data lakes webinar to get the whole story.





